CUDA学习——编程入门
CUDA 编程极简入门
GPU 不是独立的计算平台,需要与 CPU 协同工作。我们常说的用 GPU 并行计算时,其实是指 CPU+GPU 的异构计算架构。CPU 所在位置为主机端(host),而 GPU 所在位置成为设备端(device)。
CUDA 编程模型基础
典型的 CUDA 程序的执行流程如下:
- 分配 host 内存,进行数据初始化(initalize)
- 分配 device 内存,host => device 内存拷贝
- 调用 CUDA 和函数,(GPU 上)完成指定运算
- 讲 device 上的运算结果拷贝回 host
- 释放 host 和 device 的内存。
CUDA 这个异构模型通过函数类型限定词开区别 host 和 device 上的函数,主要的三个函数类型限定词如下:
__global__:在 device 上执行,从 host 中调用(一些特定的 GPU 也可以从 device 上调用),返回类型必须是 void,不支持可变参数,不能成为类成员函数。注意用__global__定义的 kernel 是异步的,这意味着 host 不会等待 kernel 执行完就执行下一步。__device__:在 device 上执行,单仅可以从 device 中调用,不可以和__global__同时用。__host__:在 host 上执行,仅可以从 host 上调用,一般省略不写,不可以和__global__同时用,但可和__device__同时使用,此时函数会在 device 和 host 都编译。
kernel
kernel 是 CUDA 中的一个重要概念,实在 device 上线程中并行(启动很多个线程)执行的函数。一个 kernel 启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的全局内存空间。一个 grid 划分为多个线程块(block),每个 block 包含很多线程(thread),整体看像是很多线程池构成的线程网。
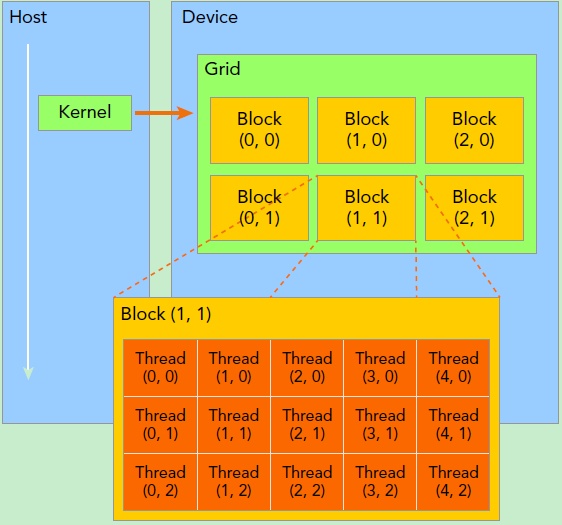
grid 和 block 都定义为dim3类型变量。dim3可以看成是包含三个无符号整数(x,y,z)成员的结构体变量,在定义时,缺省值初始化为 1。因此 grid 和 block 可以灵活地定义为 1-dim,2-dim 以及 3-dim 结构。
kernel 在调用时也必须通过执行配置<<<grid, block>>>来指定 kernel 所使用的线程数及结构。
有时候,我们要知道一个线程在 blcok 中的全局 ID,此时就必须还要知道 block 的组织结构,这是通过线程的内置变量 blockDim 来获得。它获取线程块各个维度的大小。对于一个 2-dim 的 block \((D_x,D_y)\) ,线程 \(x,y\) 的 ID 值为 \((x + y*D_x)\) ,如果是 3-dim 的 block \((D_x,D_y,D_z)\) ,线程 \((x,y,z)\) 的 ID 值为 \((x+y*D_x+z*D_x*D_y)\) 。另外线程还有内置变量 gridDim,用于获得网格块各个维度的大小(类似于 shape)。
kernel 的这种线程结构天然适合 vector,matrix 等运算。
逻辑层与物理层
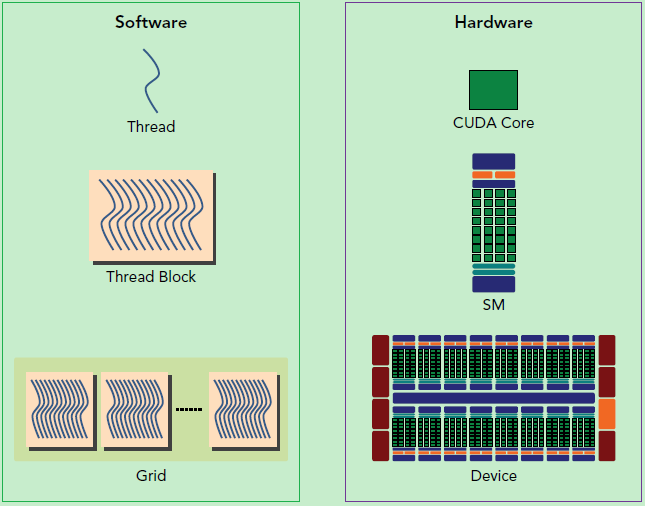
还有重要一点,你需要对 GPU 的硬件实现有一个基本的认识。上面说到了 kernel 的线程组织层次,那么一个 kernel 实际上会启动很多线程,这些线程是逻辑上并行的,但是在物理层却并不一定。这其实和 CPU 的多线程有类似之处,多线程如果没有多核支持,在物理层也是无法实现并行的。但是好在 GPU 存在很多 CUDA 核心,充分利用 CUDA 核心可以充分发挥 GPU 的并行计算能力。GPU 硬件的一个核心组件是 SM,前面已经说过,SM 是英文名是 Streaming Multiprocessor,翻译过来就是流式多处理器。SM 的核心组件包括 CUDA 核心,共享内存,寄存器等,SM 可以并发地执行数百个线程,并发能力就取决于 SM 所拥有的资源数。当一个 kernel 被执行时,它的 gird 中的线程块被分配到 SM 上,一个线程块只能在一个 SM 上被调度。SM 一般可以调度多个线程块,这要看 SM 本身的能力。那么有可能一个 kernel 的各个线程块被分配多个 SM,所以 grid 只是逻辑层,而 SM 才是执行的物理层。SM 采用的是 SIMT (Single-Instruction, Multiple-Thread,单指令多线程)架构,基本的执行单元是线程束(wraps),线程束包含 32 个线程,这些线程同时执行相同的指令,但是每个线程都包含自己的指令地址计数器和寄存器状态,也有自己独立的执行路径。所以尽管线程束中的线程同时从同一程序地址执行,但是可能具有不同的行为,比如遇到了分支结构,一些线程可能进入这个分支,但是另外一些有可能不执行,它们只能死等,因为 GPU 规定线程束中所有线程在同一周期执行相同的指令,线程束分化会导致性能下降。当线程块被划分到某个 SM 上时,它将进一步划分为多个线程束,因为这才是 SM 的基本执行单元,但是一个 SM 同时并发的线程束数是有限的。这是因为资源限制,SM 要为每个线程块分配共享内存,而也要为每个线程束中的线程分配独立的寄存器。所以 SM 的配置会影响其所支持的线程块和线程束并发数量。总之,就是网格和线程块只是逻辑划分,一个 kernel 的所有线程其实在物理层是不一定同时并发的。所以 kernel 的 grid 和 block 的配置不同,性能会出现差异,这点是要特别注意的。还有,由于 SM 的基本执行单元是包含 32 个线程的线程束,所以 block 大小一般要设置为 32 的倍数。
NVIDA CUDA 编程指南浏览
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!