算法与数据结构学习——线索二叉树
引入
在之前的学习中,我们能够感觉到,二叉树的非递归遍历需要用到栈结构的原因是需要之前遍历的信息。
以二叉链表作为存储结构时,只能找到结点的左、右孩子信息,而不能直接得到结点在任一序列中的前驱和 后继信息,这种信息只能在动态过程中才能得到。
我们想保存这个信息,该怎么办?
通过考察各种二叉链表,不管形态如何,空链域的个数总是多过非空链域的个数。 准确的说,n 个结点的二叉链表共有 2n 个链域,非空链域为 n-1 个,其中的空链域必定有 n+1 个。如下图所示。
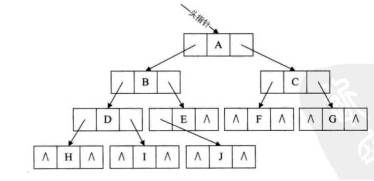
实际上,我们可以利用好这些空链域来存放结点的前驱和后继信息。
线索二叉树
1 | |
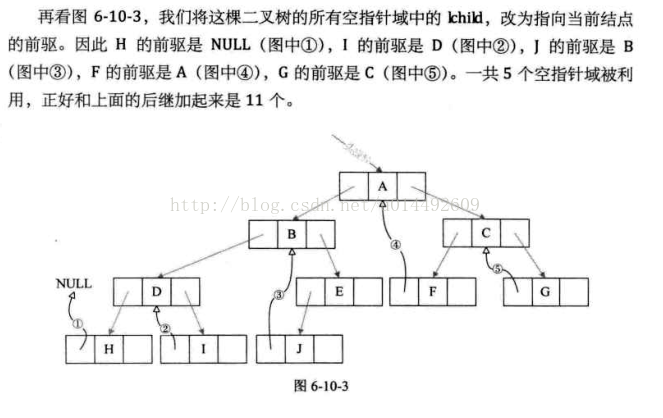
线索化的实质就是将二叉链表中的空指针改为指向前驱或后继的线索。 由于前驱和后继信息只有在遍历该二叉树时才能得到, 所以,线索化的过程就是在遍历的过程中修改空指针的过程。 遍历即线索化过程。
1 | |
中间代码做的事情:
对中间结点的左孩子判断(是否存在直接前驱),如果不存在的话左孩子的指针并不是空,而是指向保存的前驱结点。 同时对前驱结点的右孩子判断(是否存在直接后继),如果不存在的话指向当前的结点。
如图:

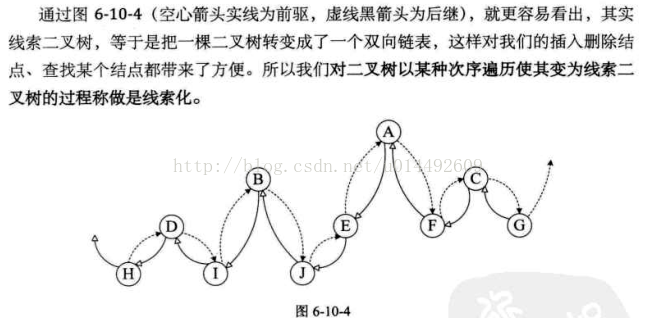
完成前驱和后继以后,线索二叉树的遍历,实际上等于操作一个双向链表结构。
如图:
参考博客
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!