CCFADL105——面向下一代计算的开源芯片与敏捷开发方法
面向下一代计算的开源芯片与敏捷开发方法
主讲人:包云岗老师(中科院计算所, 先进计算机系统研究中心)
Memory Wall
提出背景:System Architecture
1995 年提出,成为体系结构研究的最重要问题之一
- 多核处理器的流行
- 延迟与带宽显得更为重要
应对思路
- 工具模型:HMTT、C-MAT
- 预取技术:Memory Hierarchy
- 新型存储:3D Stack、HBM、NVM
- 新架构: Process-in-Memory、Domain-Specific Architecture
HMTT 访存监控仪器
包老师博士期间的工作,现在已经迭代了几个版本。
- 需求
- 安捷伦等逻辑分析仪:无法检测到云计算环境下多应用混合后的数据通路中的应用访存行为(不具备对应用进行带语义的监控)
- 提出软硬件协同监测新方法,研制HMTT 访存监控仪
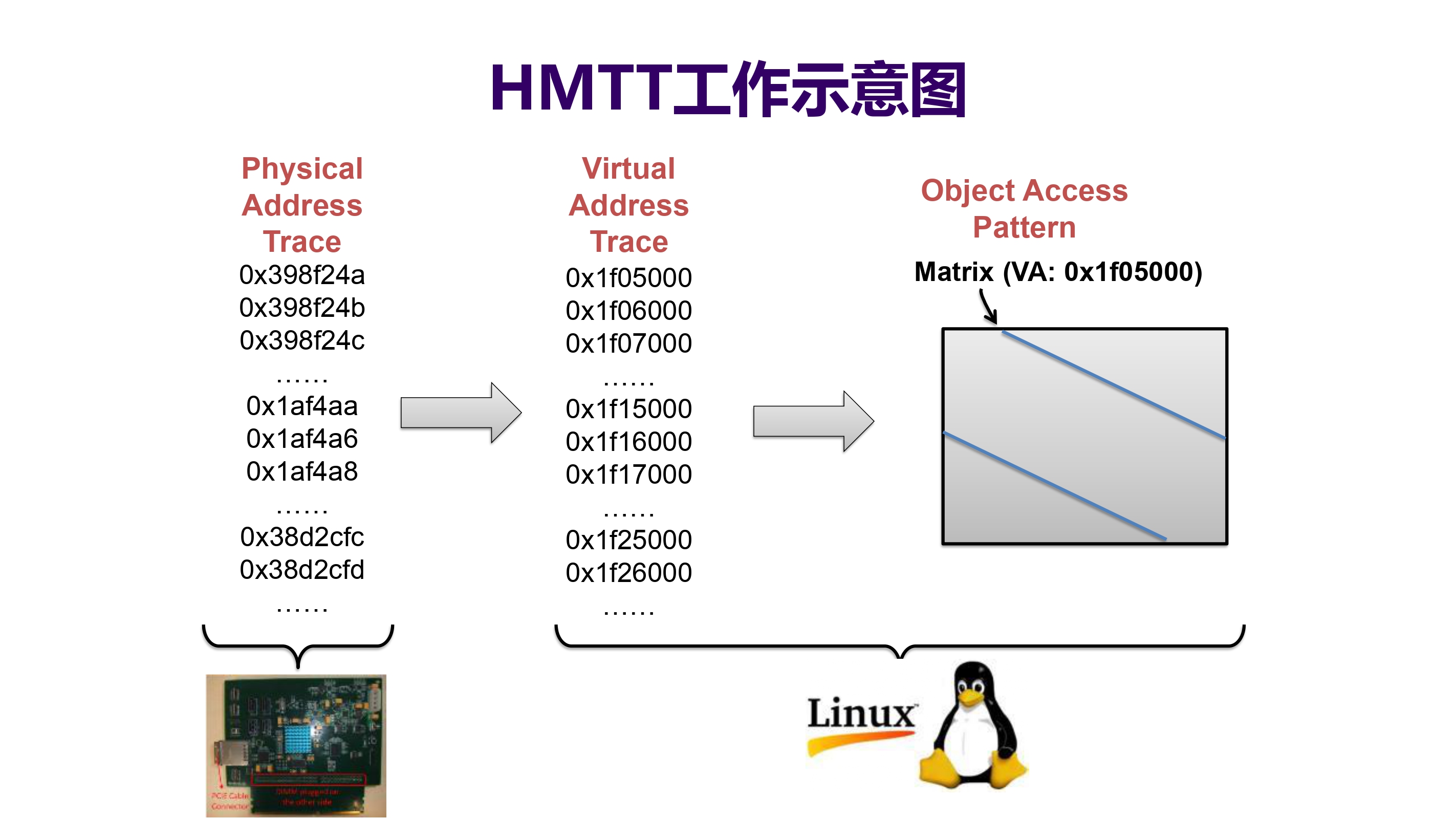
- 工作流程
- 物理地址追踪(Physical Address Trace):作为硬件,不影响其性能,直插在内存槽获取其物理地址
- 虚拟地址追踪(Virtual Address Trace):转换成虚拟地址以了解进程相关的信息
- 访问对象(Object Access Pattern):通过对虚拟地址的再分析,与变量关联起来
工作示意图如下
软件挑战
虚拟地址到物理地址的重映射技术我们上课都学到过,可是如何从物理地址反过来获取虚拟地址呢?
如何物理地址翻译为进程的虚拟地址(物理地址->软件语义信息)
解决:修改 Kernel
- 通过修改内核使得硬件可以获取到页表的 page table
- 在导出的页表中反查物理地址,获得进程产生的虚拟地址
问题:
- 扫描当前页表
- 缺页替换则对应不同进程信息
- 如何同步更新 HMTT 硬件信息
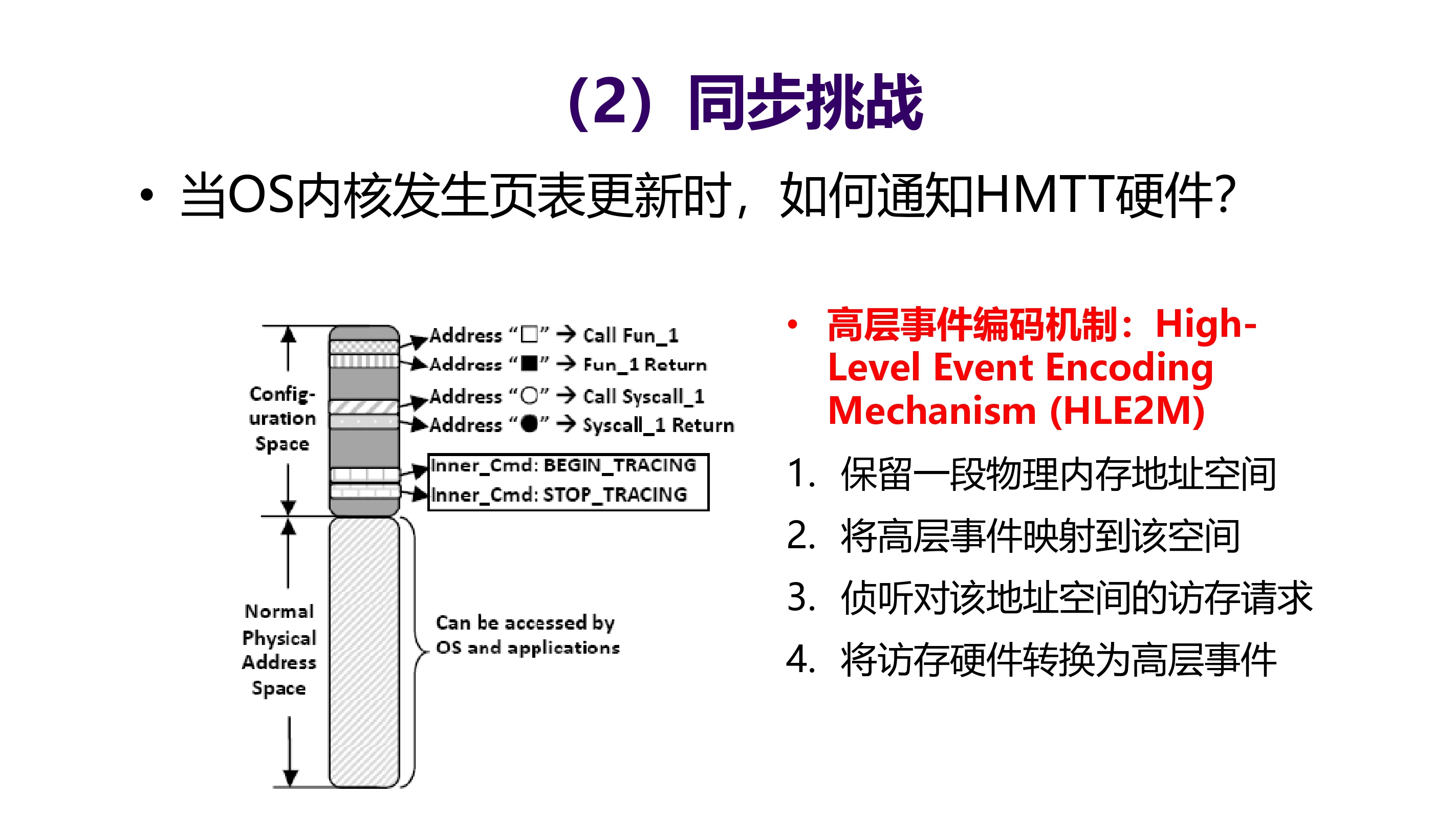
同步挑战
当 OS 内核发生页表更新时,如何通知 HMTT 硬件
解决:高层事件编码机制:High-Level Event Encoding Mechanism(HLE2M)
- 保留一段物理内存地址空间
- 将高层事件映射到该空间
- 侦听对该地址空间的访存请求
- 将访存硬件转换为高层时间
理解:将高层事件多一个分支结果,访问这一小块内存空间(相对集中),就如同一段标记数组,用来记录访存情况(次数)。
图示:
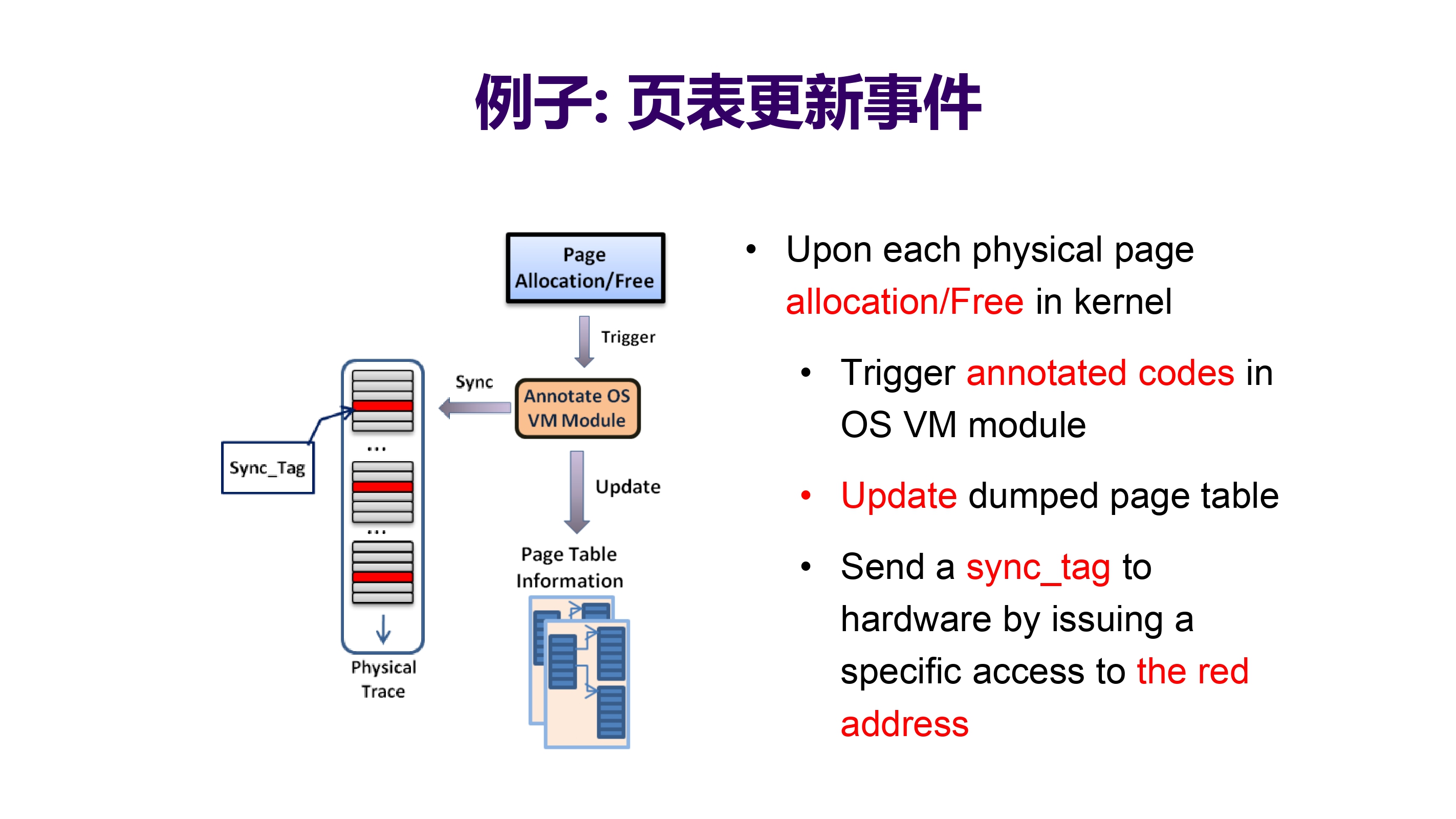
以页表更新事件为例(举一反三,其他高层事件也可以比如 CPU/DMA 访问,加锁操作):
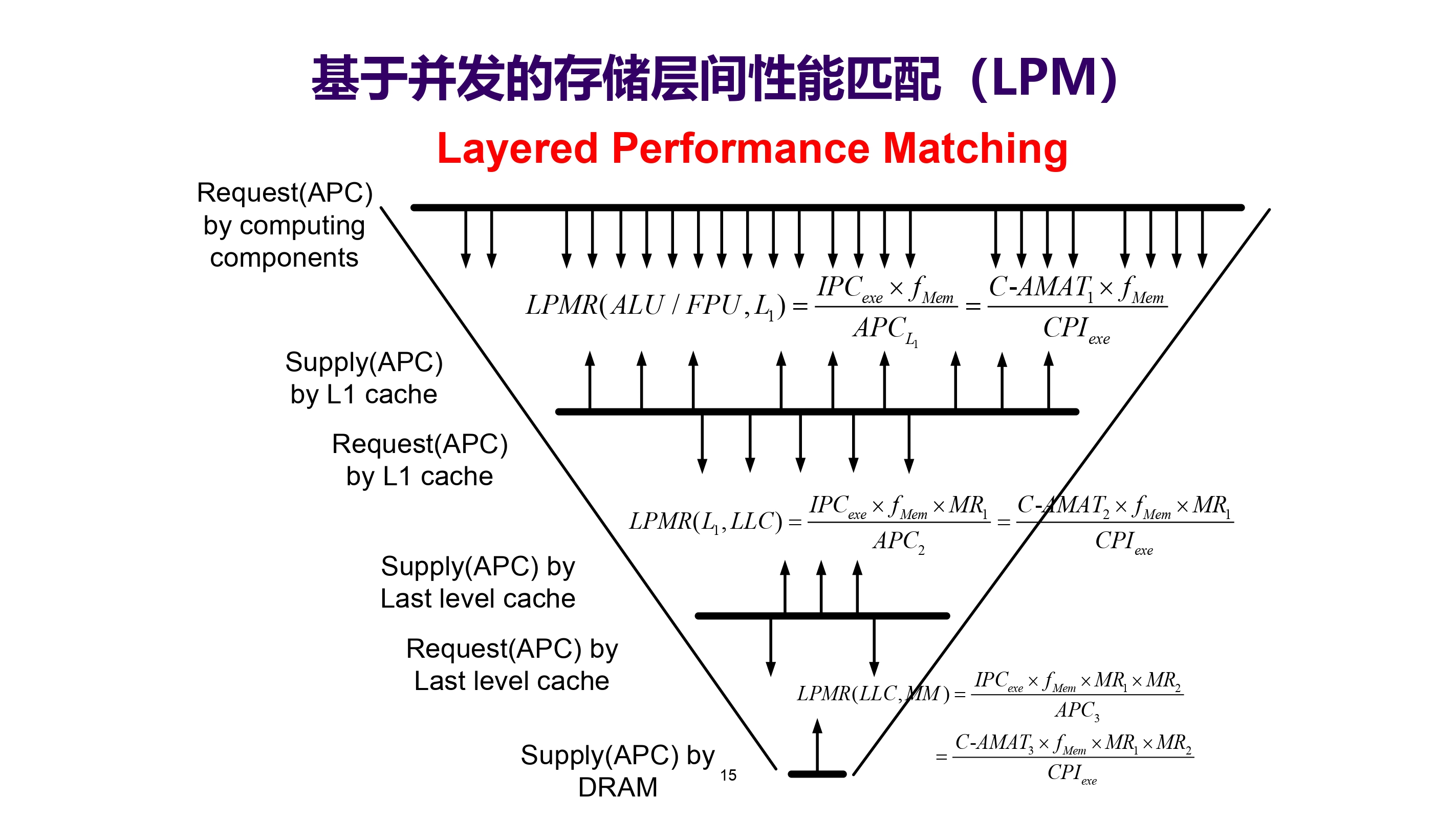
模型分析
系统结构的并发度没有被充分利用或优化利用
更多资料来源,刘宇航副研究员,中科院计算所
基于并发的存储层间性能匹配(LPM),漏斗状,如下图
数据预取
何为数据预取?将未来所需要访问的数据提前取到更靠近处理器的 Cache 中,可以有效隐藏访存延迟
需求:
- 手机处理器对于敏捷反应,以及其他落地应用的需求
- 苹果是个黑洞(闭环自研)
- 华为与科研机构的合作使得需求更明晰
学术界的研究情况:
- 提出了多种预取策略,如顺序预取,Stride 预取,马尔科夫预取...
- 主要针对 Memory Hierarchy 的某个特定层次,如 L1 Cache 或者 L2 Cache
领域专用体系结构 DSA
Domain Specific Architecture(DSA,即针对应用领域做优化的处理器架构,区别于通用架构)。
从普通码农用 python,到算法工程师从数据结构算法上优化,如果懂得并行化算法的人,还可以在并行度上优化,在往上还可以做内存优化和指令级优化,整体性能提升是惊人的。
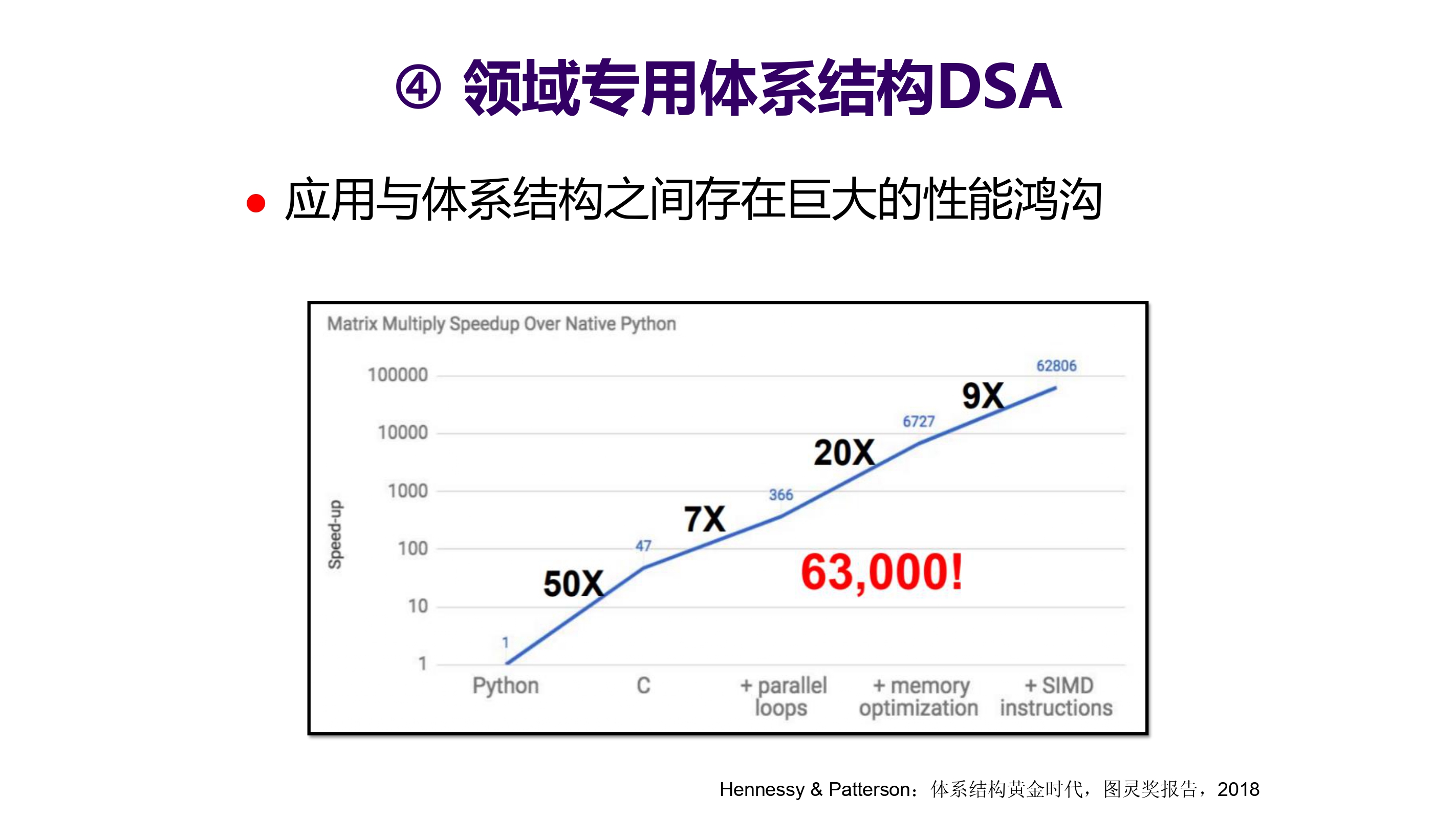
若将“人”的经验固化到芯片中去,是一件听起来很美妙的事情。
性能差异来源分析
- 并行度挖掘不够?
- 数据移动开销太大?
DSA:是道,非术
- DSA 是一种理念,尚未形成通用的技术方案
- DSA 未来可能的形态
- 每个解决方案对应一颗 SoC 与适配软件
- 每颗 SoC 包括
- 一个通用的基础平台,如 RISC-V + AXI
- 若干个领域加速器,如 APU、BPU、NPU
- 芯片敏捷开发工具
- Chisel + OpenEDA + ...
- 低门槛开发平台与制造渠道
标签化体系结构
研究历程,拆解核尝试(失败),MicroBlaze(非开源,受挫),开源指令集 RISC-V 基础上实现(成功)
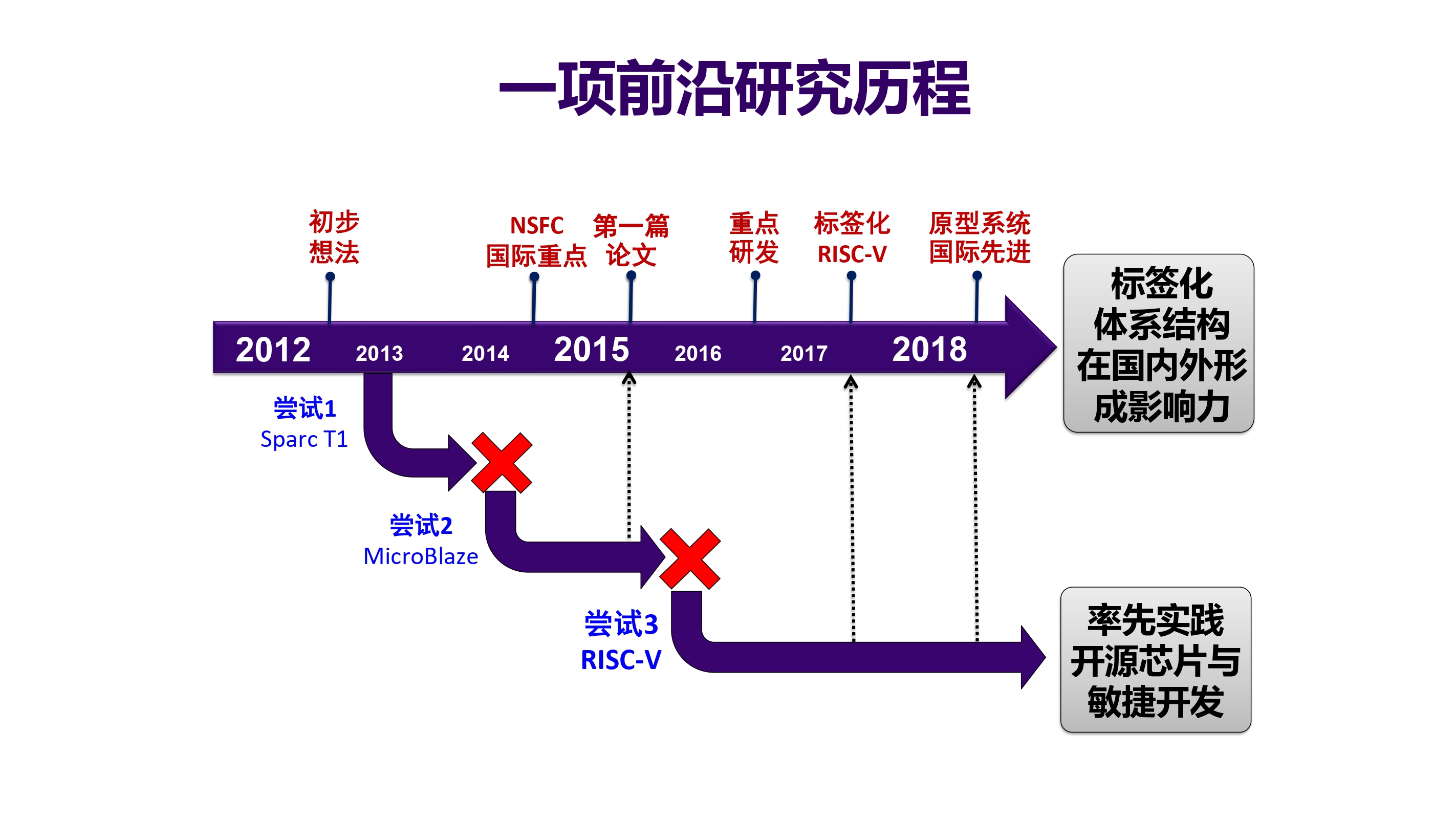
背景介绍
如之前 HMTT 的思想,希望实现新的接口,使得高层软件的信息可以传递到底层硬件中去,底层对上层有意识而采取更具针对性的解决,提高效率(而非像现在一样,底层对上层完全 unawareness)。
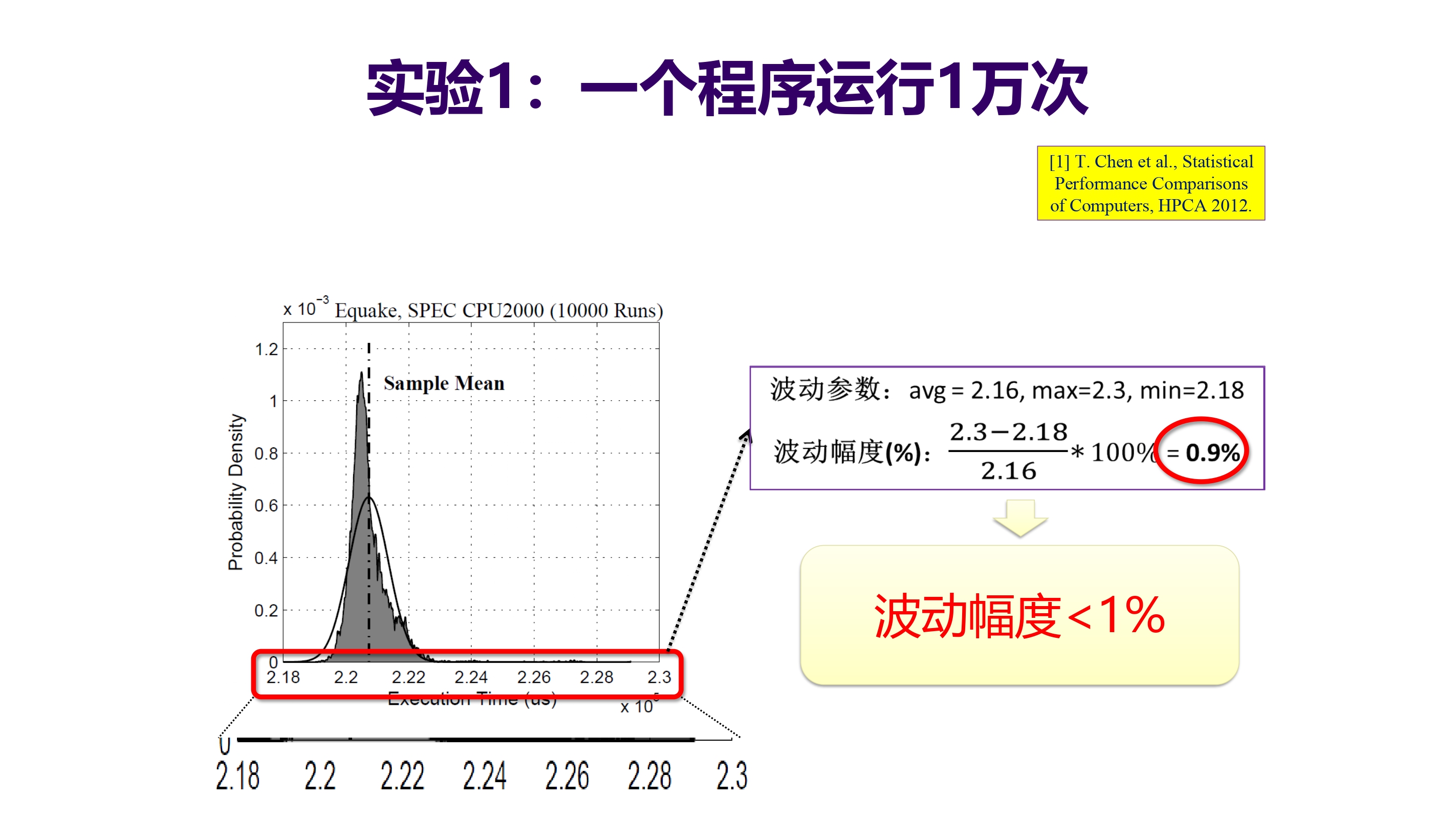
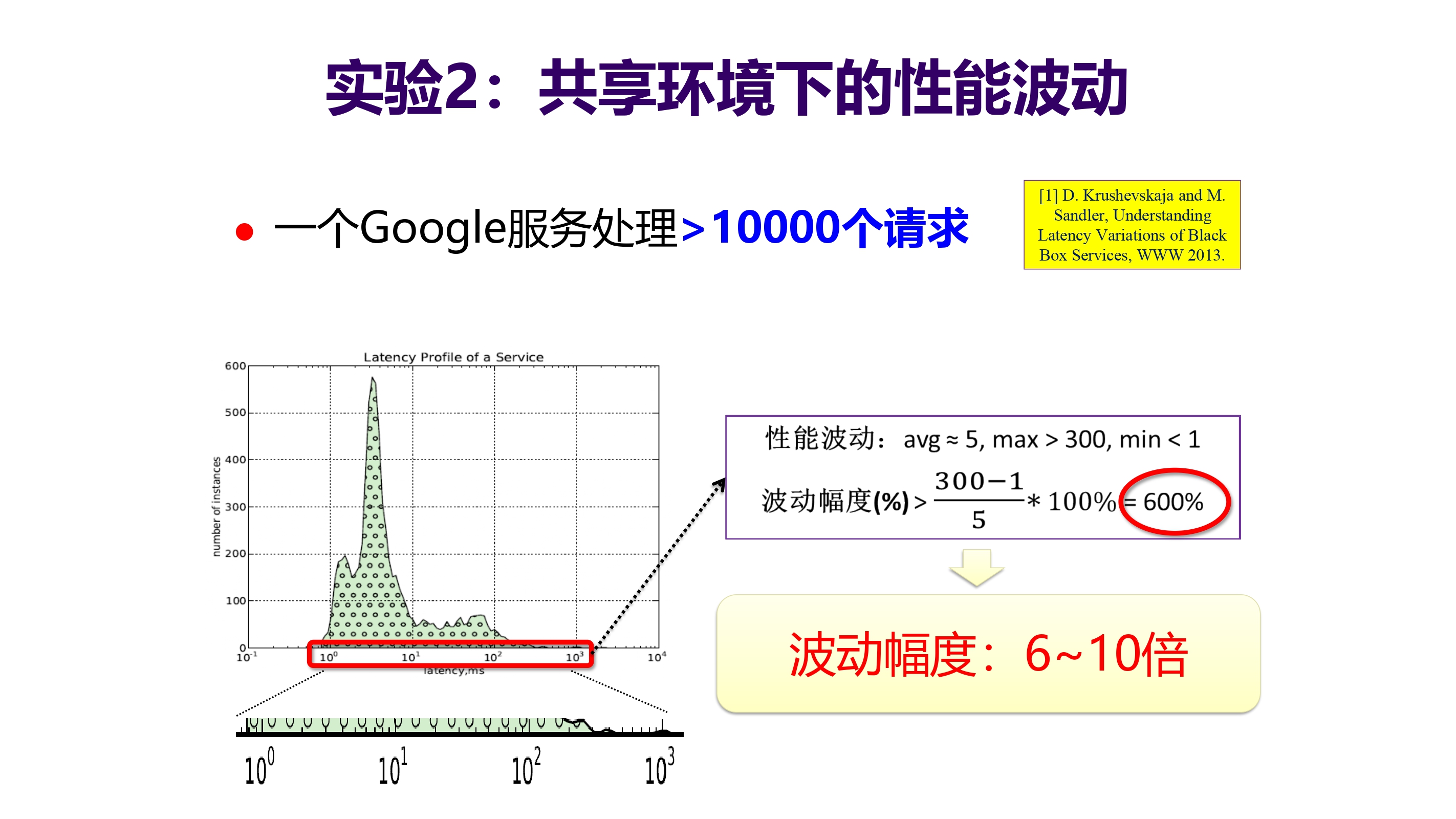
单任务稳定环境下性能波动与共享环境下的性能波动的两个实验:
需求场景
航空航天等实时场景
- 机载计算机关闭多核以保证实时性
- 美国联邦航空管理局 FAA出台相关白皮书
用户体验敏感场景
- 手机芯片内部多部件竞争冲突,操作卡顿,影响用户体验
亟需体系结构的创新
控制与弱化控制
回顾历史,重新审视冯·诺依曼结构:
- 体系结构中的控制
- 1953 年,图灵奖得主 Maurice Wikes 提出微程序来设计处理器的控制单元
- 控制被弱化
- 1980 年,RISC 成为主流,体系结构研究主要关注部件与数据通路的设计与优化,弱化了控制
但是弱化控制随着 CPU 核数,并行度要求的提高导致的问题越来越突出:性能不稳定。
共享环境下,多应用共享硬件,弱化控制会导致硬件出现无序竞争,进而引起严重的性能波动,Data Shuffling 犹如一条无序竞争的马路。
冯诺依曼瓶颈
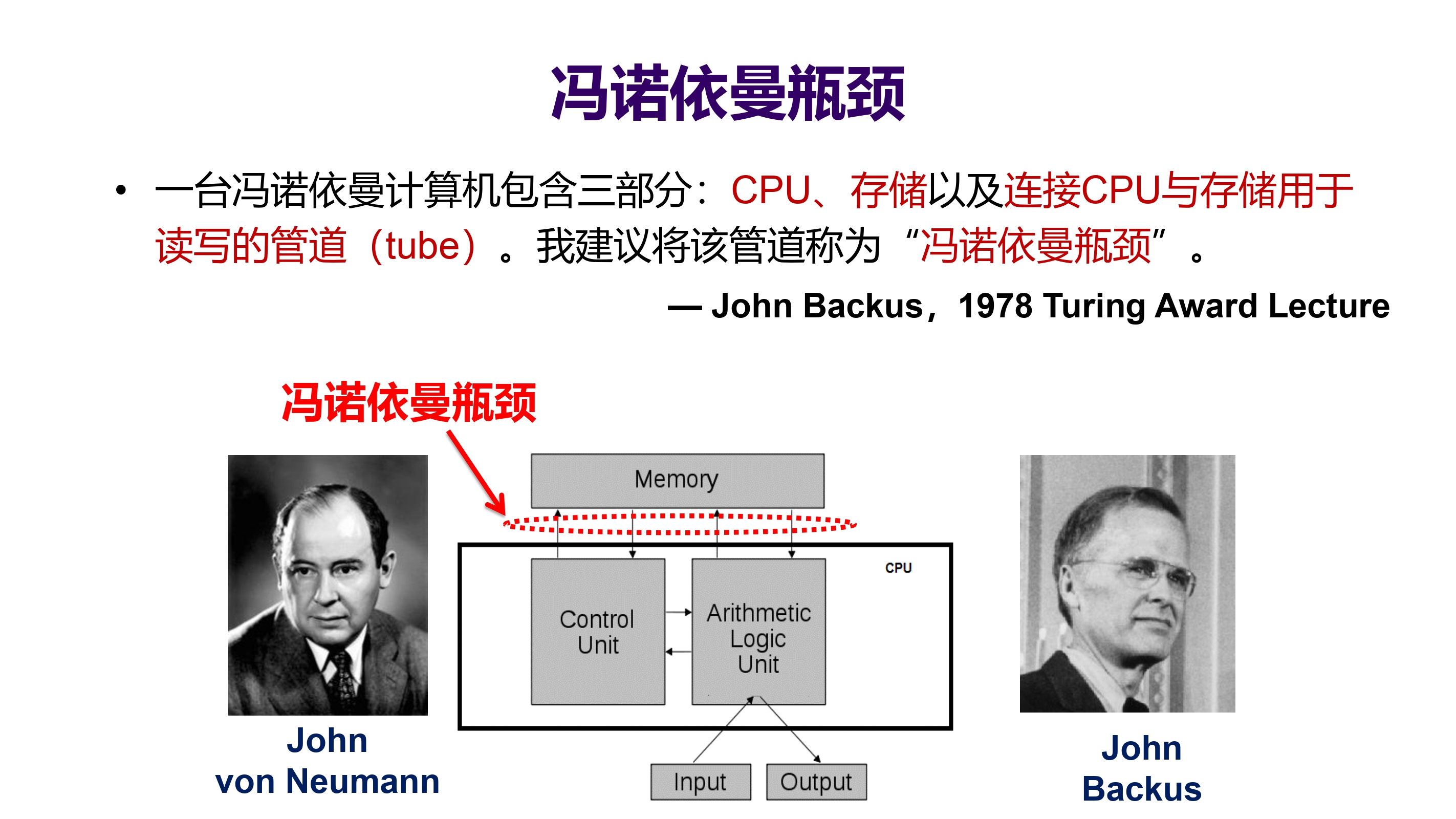
尝试方法
- 存储层次+多核
- 多核结构存储层次分化:核内+核外
- 核内 L1/L2 复制多份,共享核外 L3/Mem/IO
存在问题
无序共享导致性能无法得到保障
- 性能不确定:三级缓存(L3)共享会造成高达 3 倍以上性能下降,引起云计算“吵闹的邻居”问题。
- L3 无从判断应用的紧急程度
图示:单独可以,一同使用就出问题

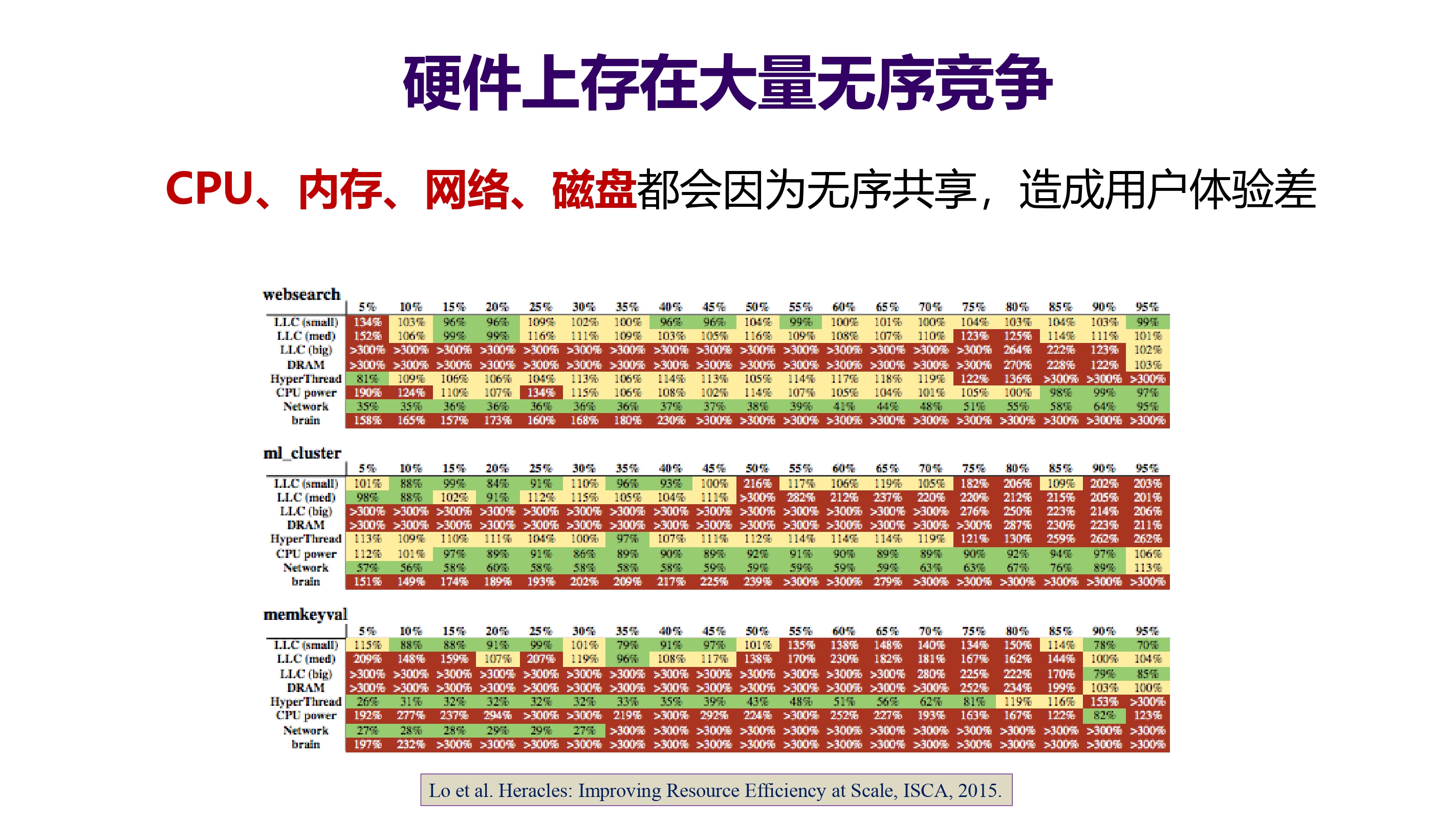
- 硬件上存在大量无序竞争
- CPU、内存、网络、磁盘都会因为无序共享,造成用户体验差。
图示
接口设计
1973 年,Feustel 教授提出 Tagged Architecture
- 核心思想是将高层语言信息传递到底层硬件
- 替代冯诺伊曼结构
设计原理:
- 所有数据赋予一个类型标签
- 标签存于内存中
- 标签触发中断进行处理
问题:
- 设计太复杂,难以实现
SDN 到计算机
2010-2012 在普林斯顿 PARSEC 研究内容:标签化网络、frenetic(一种网络编程语言)、P4
从 SDN 网络架构借鉴思路,计算机即网络(Computer as a Network),计算机本质上就是一个网络,内部的不同部件通过包进行通信——PCIe 包、QPI 包、NoC 包,......
| SDN 核心原理 | 标签化冯·诺依曼体系结构 | |
|---|---|---|
| 细粒度对象 | 每个网络包增加一个标签(Label) | 每个内部请求(如访存请求)增加一个标签 |
| 关联语义 | 标签值与用户的网络需求关联 | 标签值与上层 VM/进程/线程/变量等关联(高层信息) |
| 携带传播 | 网络包传播过程中携带标签 | 标签在计算机访问各个存储层次过程中全程携带 |
| 标签控制逻辑 | 网络设备基于标签控制网络包转发 | 基于标签的请求区分处理(底层高效) |
从 SDN 到计算机,从标签化网络到标签化冯诺依曼体系结构
业界尝试:2016 年 Intel RDT 技术、PARD
最小污染原则
| 70 年代标签体系结构失败原因 | LvNA 的三条“最小污染”规则: |
|---|---|
| 所有数据赋予一个类型标签 | 标签应尽可能简单 |
| 标签存于内存中 | 标签存于请求中 |
| 标签触发中断进行处理 | 控制逻辑放置在数据通路上 |
增加标签寄存器,标签关联硬件虚拟机,传播标签,可编程控制逻辑
尝试与实现
尝试 1:基于 MCU(微控制单元)的控制逻辑,尝试 2:基于表的控制逻辑
尝试 2:基于表的控制逻辑
集中平台资源管理
- 连接所有控制逻辑形成控制平面
- 运行基于 Linux 的固件
- 将控制逻辑抽象为文件
实现
- Full-system cycle-accurate simulator
- FPGA prototype on Xilinx VC709 evaluation board
- MicroBlaze version \(\times\)
- RISC-V version \(\checkmark\)
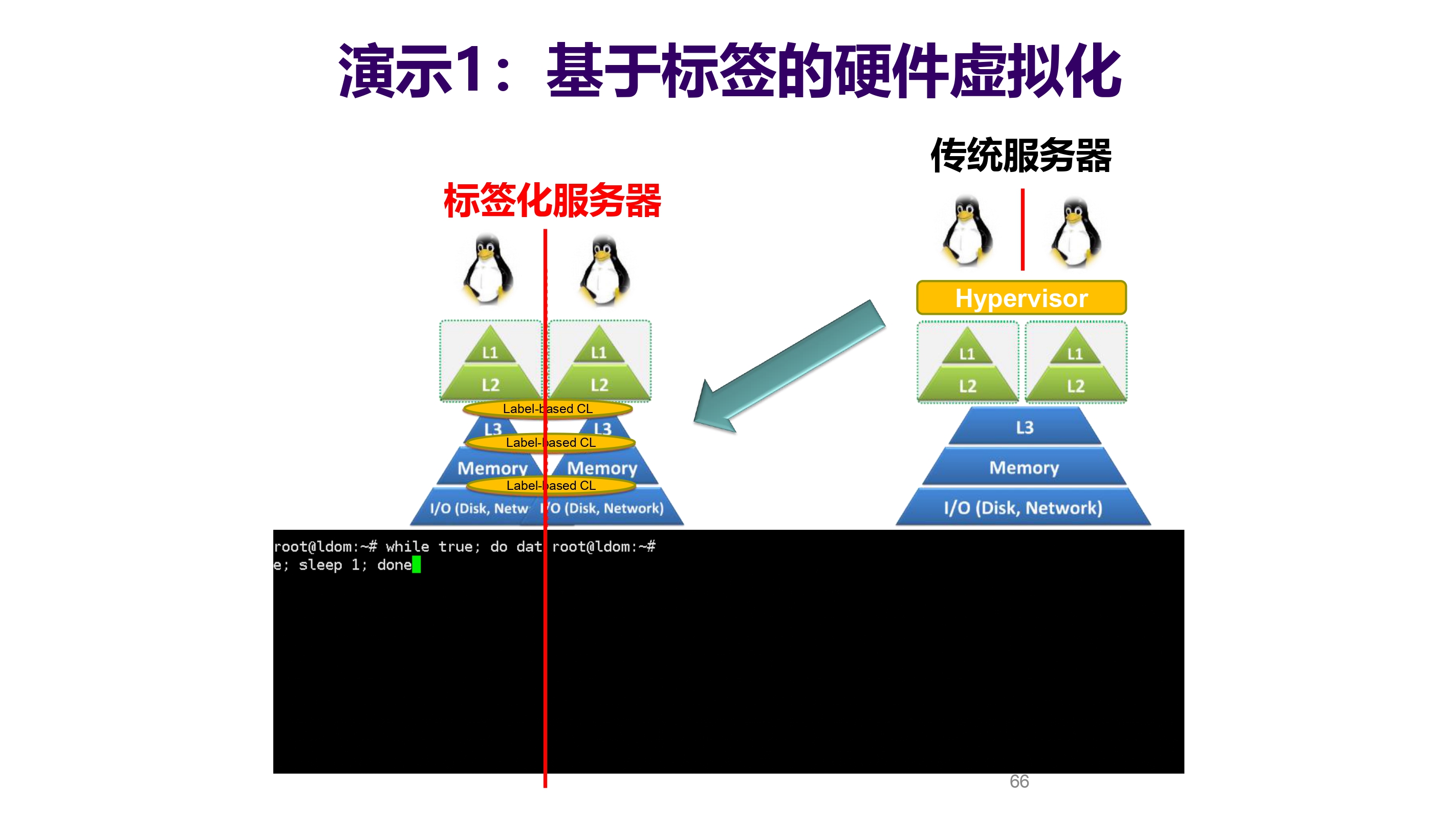
演示
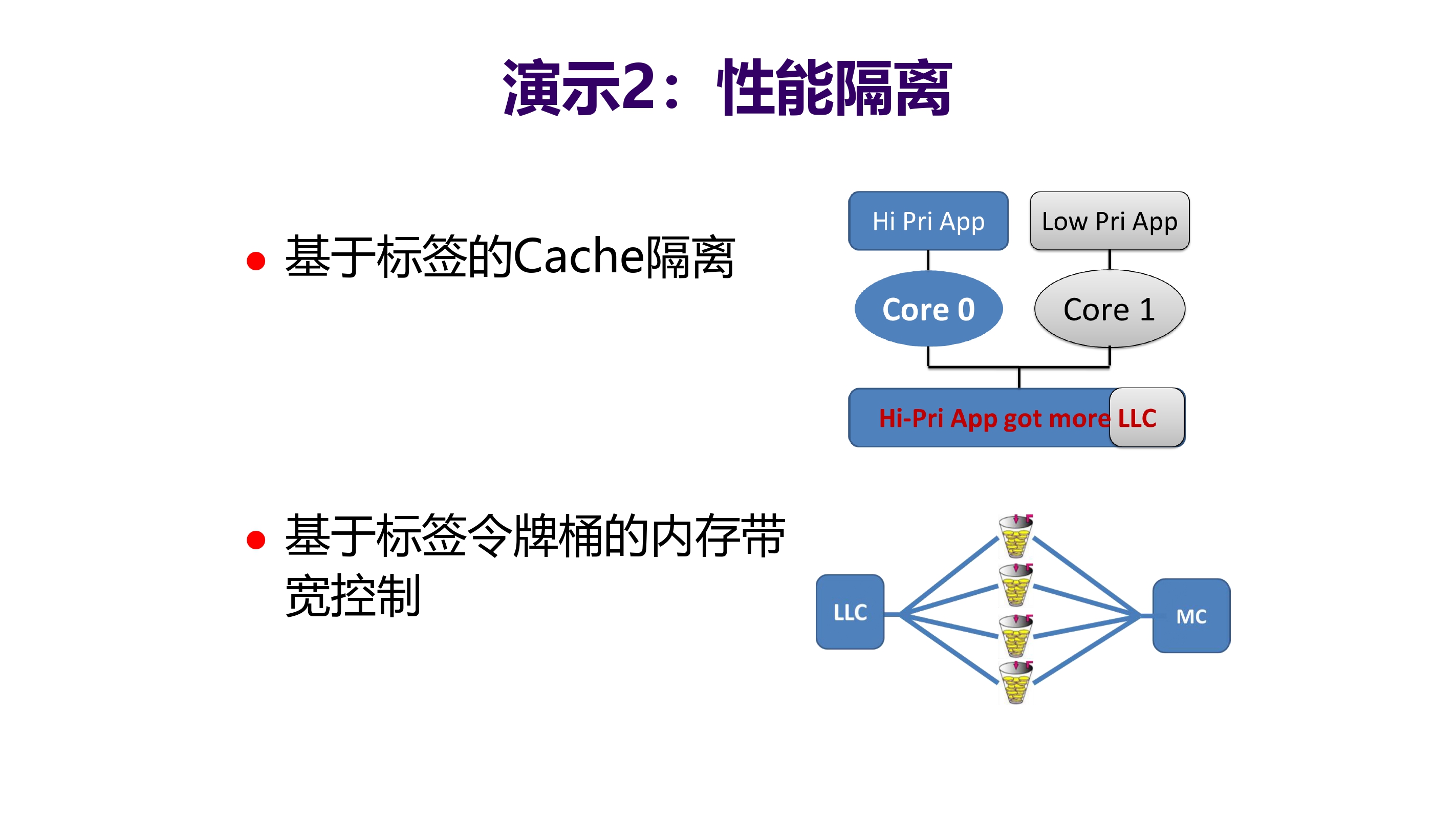
硬件资源动态调整的共性问题
本质问题:如何在混合环境下预测出应用单独运行时需要的资源?
- 解决方法 1:离线分析建模,预测动态资源需求
- 解决方法 2:在线实时预测动态资源需求
- Shadow X 机制:针对不同资源设计一套影子资源模型,模拟推断应用单独运行时所需资源
| 共享模型 | Shadow X 机制 |
|---|---|
| SMT | 利用Shadow Table获得 PTA 资源(ICS2019) |
| LLC | 利用Shadow Tag来获得一条 hit rate 曲线 |
| Mem Bandwidth | 利用Shadow 感知机获得内存宽带 |
实现自动 LLC 管理和自动访存宽带管理
芯片验证:与 771 所合作,正在开展 8 核 Labeled RISC-V 流片
同行进展
ARM 正在研究基于标签的MPAM技术:Memory Partitioning and Monitoring
学习教程
作者提供的教程 Labled ISC-V: A Case for Software-Defined Architecture
开源芯片与敏捷开发
主要讲了当前局势和芯片开发学习的未来。
- 中国高科技企业正面临美国技术“核打击”
- 优秀人才储备严重不足
- 如果认为 ISCA 论文第一作者是行业专业技术佼佼者
- 十年来 85%选择在美国就业,仅 4%在中国就业
- 芯片设计门槛高,大学无能力培养优秀人才
- 时间长
- 成本高
- 降低芯片门槛是人才危机一种破解之道
- 美国经验:MISIS 项目,为大学提供流片服务。
领域专用体系结构星期
如何弥补软硬件性能鸿沟?
- 硬件加速器
- 领域专用体系结构(DSA Domain Specific Architecture)
开源芯片,降低芯片设计门槛
RISC-V 国际开源实验室(RIOS)成立
大卫·帕特森(David Patternson)在瑞士宣布依托清华-伯克利深圳学院建设 RIOS(RISC-V International Open Source Laboratory)实验室,全面提升 RISC-V 生态系统至最先进水平。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!