分布式系统学习——MIT6.824-Lecture1课堂笔记
Lecture 1: Introduction
什么是分布式系统
- 多台机器共同协作
- 大型网站的存储,MapReduce,P2P 文件共享,&c
- 许多关键基础设施是分布式的
为什么需要(选择)分布式
- 为了连接,组织物理上分离的实体
- 为了通过隔离(isolation)实现安全性
- 为了通过备份(replication)实现容错性
- 为了通过并行的 CPUs,内存,硬盘,网络,实现扩容
担心的地方
- 多个并发部分导致的复杂性问题
- 必须处理部分部分失败的情况
- 难以发挥性能潜力
为什么选择这门课
- 有趣 -- hard problems, powerful solutions
- 应用在实际系统中 -- 被大网站的崛起驱动
- 活跃的研究领域 -- 许多进展产生,同时又有很多待解决的问题
- 上手做 -- 在 labs 实验中会自己动手建立严密的系统
课程组成
课程
大的想法,论文讨论和实验
阅读
研究文献包含经典的和新颖的,文章描述了主要思想和重要的细节。许多 Lec 关注点都放在论文上。请课前阅读研究论文,否则你会觉得上课内容很无聊,而且你无法不费力地学会, 每篇论文都有为你准备的小问题,请务必给我们发送你阅读论文的时候存在的疑问, 晚上十点前给我们发送问题和答案。
两次考试
期中期末考试
实验
实验目标:
- 深入理解一些重要的技术
- 掌握分布式编程经验
- 每周一个
实验安排:
- Lab 1: MapReduce
- Lab 2: replication for fault-tolerance using Raft
- Lab 3: fault-tolerant key/value store
- Lab 4: sharded key/value
主题
这是一门关于会被应用程序抵用的基础设施的课程,它会对应用程序隐藏分布式系统的复杂性而进行抽象,包括下面的三个抽象
- 存储(Storage)
- 通讯(Communication)
- 计算(Computation)。
上述主题会被重复提及。
主题:实现(implementation)
- RPC 技术, 线程 threads, 并发控制 concurrency control
主题:性能(performance)
理想目标:可伸缩的吞吐量。
通过购买更多的机器就可以实现更大的负载。
随着数量增长,扩展变得困难
负载不均衡,straggler 问题。
不可并行的代码段:如初始化 initialization, 交互 interaction。
由共享资源引起的 Bottleneck,比如网络。
一些无法通过扩展解决的新跟那个问题
比如降低用户相应耗时,可能更需要编程人员的工作而非更多的机器。
主题:容错(fault tolerance)
- 数千台机器加上复杂网络,总会 something broken,我们希望对应用程序掩藏这些故障,同时我们还希望:
- 高可用性(Availability)——即便出现故障,应用程序仍能工作。
- 暂时性(Durability)——故障修复后应用会回归到正常状态。
重要理念:复制服务器。
如果一个服务器崩溃了,客户可以转而使用其他复制的服务器。
主题:一致性(Consistency)
- 多用途的底层设施需要良定义的行为。例如: Get(k) 获取到的值应该是最近的 Put(k,v)设置的。
- 但实现良好行为是很困难的
- 复制的服务端难一实现完全统一。
- 客户端在进行多步更新的中途崩溃。
- 服务端在尴尬时刻崩溃,比如执行完成但没来得及反馈信息。
- 网络可能会使存活的服务器看起来跟挂了一样;存在“脑裂的风险“
案例学习: MapReduce
让我们将 MR 作为一个案例进行讨论。 MR 是课程 6.284 主题的一个很好的例子,也是实验 1 的主要关注点。
MapReduce 概要
背景: 几个小时处理完 TB 基本的数据集 例如:实验分析爬行网页的结构,通常不是由分布式系统开发的爱好者开发的这就会非常痛苦,如如何处理错误。 总体目标: 非专业程序员可以轻松的在合理的效率下解决的巨大的数据处理问题。程序员定义 Map 函数和 Reduce 函数、顺序代码一般都比较简单。 MR 在成千的机器上面运行处理大量的数据输入,隐藏全部分布式的细节。
MapReduce 的抽象视图
- 输入原始数据集为
<k1,v1> - MR 调用在每个分片上调用 Map()函数,产生中间数据集
<k2,v2>(每日此 Map()调用称为一个 Map 任务),并且聚集相同k2值的v2,并将它们传送给 Reduce()函数调用。 - 最后的输出是数据集
<k2,v3> - MapReduce API -- map(k1,v1) -> list(k2,v2) -> reduce(k2, list(v2)) -> list(k2, v3)
MapReduce 举例
1 | |
MapReduce 隐藏的细节
MR 隐藏了很多让人痛苦的细节
- 如何在 server 上启动 s/w 任务
- 如何跟踪哪个任务是完成的
- 数据传输(data movement)
- 错误恢复
MapReduce 易实现扩展
N 台计算机可以同时执行 Nx 个 Map 函数和 Reduce 函数,Map()可以并行执行,因为他们不需要交互(相互等待或共享数据)。Reduce()工作也一样
他们之间的交互仅有 maps 和 reduces 之间的数据传送("shuffle")。
因此你可以通过购买更多的计算机来获得更大的吞吐量,而非应用专用的高效并行,计算机要比程序员便宜得多。
什么限制了性能
We care since that's the thing to optimize.
CPU?内存?硬盘?网络?
MR 的数据传输都是通过网络进行的,而网络的全内容量通常远小于主机网络链接速度,因此更加关心减少通过网络传输的数据。
更多细节(文章图 1)
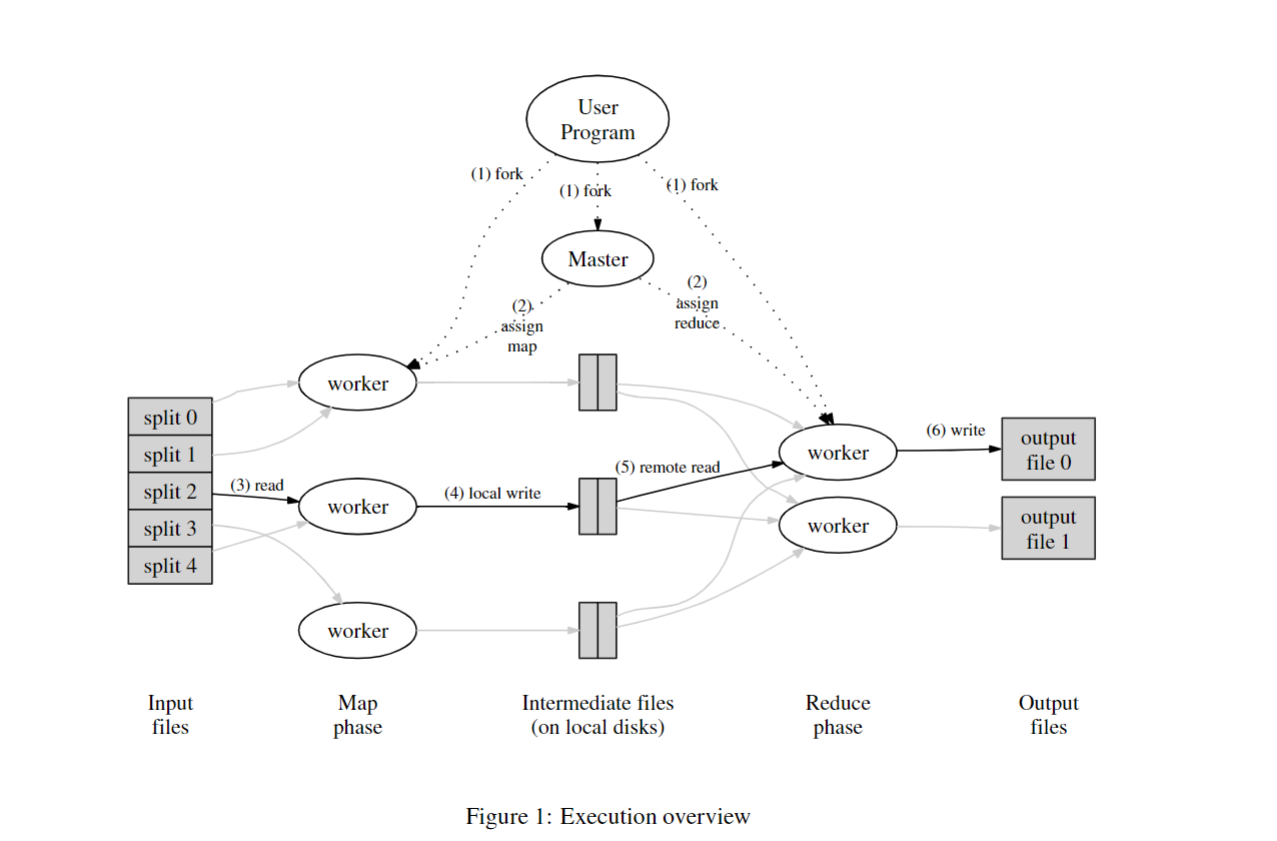
- master:给 workers 分配工作,记录中间输出的位置。
M/R task: 输入分割,输入存储在 GFS,每个拷贝三份,全部电脑都运行 GFS 和 MR workers,对于输入的分片远远多于 worker 的数量,master 会让每台机器上面均执行 Map 任务,并在当原来的任务完成之后会处理新的任务,
worker 按中间输出的 key 哈希(hash)输出到对应 R 分区保存在本地硬盘上,(提问:这样的实现有什么优势?) 当全部 Maps 任务完成时, Reduces 任务将会开始执行。master 告诉 Reducers 去获取 Map workers 产生的中间数据分区,Reduce worker 将最终的结果输出到 GFS。
有哪些详细的设计帮助提示网络性能
- Map 的输入来自建立在本地硬盘上的 GFS 副本而非网络。
- 中间数据只在网络上面传输一次,Map worker 产生的中间输出保存在本地硬盘,而不是 GFS(不会传 1 备 3)。
- 中间数据通过 key 被划分到多个文件,”大网络传输“更加有效。(问题:为什么中间数据不通过 TCP 以流的方式传输 reducer)
如何处理负载均衡
- 对扩展来说至关重要——最坏情况:剩余 N-1 个 server 等待 1 个 server 完成工作。而一些任务很有可能会比其他任务耗时更长。
- 解决方案:使任务数(task)远大于工作机(worker)的数量,根据不断完成、不断供给的方式使工作机持续工作,这样的分片不会使哪一片任务是过大的以至于影响到总的完成时间,这样快的工作机就会比慢的处理更多任务,最后一同完成整体 MR 工作。
如何处理容错
比如:如果服务器在执行 MR 工作时崩溃怎么办?隐藏这个错误非常困难(问题:为什么不重新执行整个工作呢?)
MR 只重新执行失败的 Map 函数和 Reduce 函数,他们是纯函数——他们不会改变数据输入、不会保持状态、不共享内存、不存在 map 和 map,或者 reduce 和 reduce 之间的联系,
所以重新执行也会产生相同的输出。纯函数的这个需求是 MR 相对于其他并行编程方案的主要限制,但它同时也对 MR 的简洁性起到了至关重要的作用。
处理 worker 崩溃的细节
Map worker 崩溃
- 如何发现 worker 崩溃:maskter 发现无法 ping 通 worker,崩溃导致崩溃的 worker 本地储存的中间输出丢失。
- Reduce workers 已经获取全部的中间数据,那么 master 不需要重启 Map 函数。
- Reduce workers 并未获取全部的中间数据,出发了 reduce 任务的崩溃,那么会前置重新执行依赖的失败的 map 任务。
Reduce worker 崩溃
- 输出任务是正常的 -- 储存在 GFS,伴随副本,master 必须在其他 worker 上面重新开始该任务。
- 输出过程中崩溃,GFS 会自动进行原子重命名输出,然后使其保持不可见直到 Reduce 完成,所以 master 在其他地方再次运行 Reduce worker 将会是安全的。
其他错误和问题
假如 master 意外的开启两个 Map worker 处理同一个输入(进行相同的 Map 任务)会怎么样?
它只会告诉 Reduce worker 其中的一个。
假如两个 Reduce worker 处理中间数据的同一个分区会怎么样?
它们都会将同一份数据写到 GFS 上面,GFS 的原子重命名操作会触发,避免混淆,先完成的获胜将使结果可见。
假如一个 worker 非常慢怎么办(掉队者)?
产生原因可能是非常糟糕的硬件设施。 master 会对这些最后的任务创建第二份拷贝任务执行(见原文 Backup Tasks),
假如一个 worker 因为软件或者硬件的问题导致计算结果错误怎么办?
太糟糕了!MR 假设是建立在"fail-stop"(而非拜占庭故障)的 cpu 和软件之上。
假如 master 崩溃怎么办?
从 check-point 点恢复,或放弃整个 job,(原文章意思是直接重启整个任务)。
MapReduce 模式适用性
并不是所以工作都适合 map/shuffle/reduce 这种模式
- 小的数据,因为管理成本太高,如非网站后端
- 大数据中的小更新,比如添加一些文件到大的索引
- 不可预知的读(Map 和 Reduce 都不能选择输入)
- 多重传输(Multiple shuffles), e.g. page-rank (can use multiple MR but not very efficient)
实际 Web 公司如何应用 MapReduce
总结
Conclusion MapReduce single-handedly made big cluster computation popular.
- \(\times\) 不是最高效灵活的。Not the most efficient or flexible.
- \(\checkmark\) 易于拓展。Scales well.
- \(\checkmark\) 易于编程。Easy to program -- failures and data movement are hidden.
上述几点是很好的权衡,在后续课程我们可以看到更多高级、成功的例子。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!