分布式系统学习——Raft拓展版本论文学习
Step 1
题目摘要引言
题目
寻找一个易于理解的共识算法(拓展版本)
摘要
Raft 是解决 log replication management 的分布式共识算法,相当于(multi-)Paxos 效果。为了便于理解,Raft 将共识算法的几个步骤分离开,包括leader 选举、log 复制、安全性。它强调了一致性以减少必须考虑的 states 数量(这个是不是对比 Paxos 说的)。Raft 还包括一个用 overlapping majorities(多数重叠)来改变集群成员的新机制。
引言
共识算法允许一组机器在个别成员出现故障时仍能作为一个相关联的群体持续工作。正因为如此,它们在构建可靠的大型软件系统中扮演着重要的角色。Paxos 主导了过去十年关于共识算法的讨论(算法研究、课程教学)。
- Paxos 太难理解了,而且为了支持实际系统,它的架构仍要做许多复杂的调整。
- Raft 设计初衷就是可理解性:能被实际系统应用且比 Paxos 更易于学习。
Raft 为增强可理解性,在以下方面做出努力:
- 拆解过程:将leader 选举、log 复制、安全性拆分开。
- 减少状态空间数:与 Paxos 对比,Raft 降低了不确定性程度(这个不太理解,英文是 nondeterminism)和服务器间出现不一致的方式。
Raft 新颖的特点:
- Strong leader:与其他共识算法相比,Raft 有一个更“强势”的领导者。比如,log entries 只会从 leader 开始然后影响其他 servers(flow from the leader to other servers)。
- Leader election:Raft 使用随机计时器来启动选举过程,这仅需要在现有的 heartbeats(心跳线)机制上增加一点内容,就可以快捷又迅速地解决冲突。
- Membership changes:Raft 机制对于改变集群中机器配置使用一种新的方法
joint consensus,该方法保证转换过程前后两配置下有一个重叠部分(保证一个 majority 的重叠),这样在配置转换过程中,系统仍可以正常工作。
Raft 有多个开源版本的实现并被应用于实际系统中,教学上得到更好的反馈,其安全性能也得到详细说明和证明。
基本理论概况
结论部分
启发:在算法设计过程中,可理解性同正确性、效率和简洁性同样重要。其他几个性质在开发人员将算法应用于实际系统前都无法验证。而缺少可理解性,可能会使得开发人员在实现的过程中产生误解偏离设计者的原有意图(除非开发者对算法有非常深刻的理解并具备将其实现的直觉),这就导致实现很难保证期望的性质。
本问讨论了分布式共识算法的设计问题,提出一个新的算法——Raft,相比原来广为流传的 Paxos 来说,更易于理解,且相信能为系统构建提供更好的途径。在设计途中,我们发现自己不断重复使用一些技术,例如分解问题和简化状态空间。 这些技术不仅提高了 Raft 的可理解性,而且更加容易相信它的正确性。
回答基本问题
- 类别
基于原有算法进行的新算法设计。
- 内容
Reading Group 所提到的,结合 Erasure Code 的方案——CRaft。
- 正确性
正确
- 创新点
可理解性,可理解性。
- 清晰度
清晰
阅读选择
继续阅读!
Step 2
细读笔记
状态机复制
共识算法常出现在状态机复制(replicated state machine)上下文中。一组服务器上的状态机计算相同的粗笨,这样即使其中一些服务器宕机,仍能继续工作。状态机复制常用于解决分布式系统的容错问题。
状态机复制常用 replicated log 来实现。每个服务器存储一个包含一系列命令的日志,其状态机按顺序执行这些命令。每个日志以相同的顺序包含相同的命令,因此每个状态机处理相同的命令序列。由于状态机是确定的,所以每个状态机都计算相同的状态和相同的输出序列。
而保证 replicated log 一致就是共识算法的工作。共识模块负责将客户端命令加入日志,并与其他服务器的共识模块通信以保证日志最终以相同的顺序包含相同的请求(same requests in the same order)。当命令被正确地复制,服务器地状态机就会按照日志顺序执行并将结果返回给客户端。
实际系统应用地一致性算法通常有以下特征:
- 保证 non-Byzantine 条件下的安全性(即只设计以应对 fail stop)
- 只要保证 majority(绝对多数)的机器是正常且可以通信的,系统就具备完备功能。
- 不依赖 timing 来保证一致性(这一点以前不清楚,作者解释,在最坏情况下,错误时钟和极端消息可能会导致可用性问题)。
- 通常情况下,当 majority 都回复了一次远程调用(RPC)时,命令就完成了,minority 的速度较慢的机器不会影响系统的整体性能。
Paxos 的优劣势
Leslie Lamport 的 Paxos 协议是该领域近年被讨论最多的。文章中对 Paxos 评价是这样的。
Paxos first defines a protocol capable of reachingagreement on a single decision, such as a single replicatedlog entry. We refer to this subset assingle-decree Paxos.Paxos then combines multiple instances of this protocol tofacilitate a series of decisions such as a log (multi-Paxos).Paxos ensures both safety and liveness, and it supportschanges in cluster membership. Its correctness has beenproven, and it is efficient in the normal case. Paxos 首先定义了一种协议,该协议能够就单个决定达成共识,例如单个复制日志条目。 我们将这个子集称为单命令 Paxos,然后 Paxos 组合了该协议的多个实例以促进一系列决策,例如日志(multi-Paxos).Paxos 确保安全性和活跃性,并支持集群成员身份的更改。 它的正确性已经被证明,并且在正常情况下是有效的
Unfortunately, Paxos has two significant drawbacks.The first drawback is that Paxos is exceptionally diffi-cult to understand. The full explanation [15] is notori-ously opaque; few people succeed in understanding it, andonly with great effort. As a result, there have been severalattempts to explain Paxos in simpler terms [16, 20, 21].These explanations focus on the single-decree subset, yetthey are still challenging. In an informal survey of atten-dees at NSDI 2012, we found few people who were com-fortable with Paxos, even among seasoned researchers.We struggled with Paxos ourselves; we were not able tounderstand the complete protocol until after reading sev-eral simplified explanations and designing our own alter-native protocol, a process that took almost a year. 不幸的是,Paxos 有两个明显的缺点。第一个缺点是 Paxos 非常难以理解。 完整的解释[15]非常模糊,只有很少的人能够成功地理解它。 结果,有几种尝试用较简单的术语来解释 Paxos [16,20,21]。这些解释集中在单法则子集上,但它们仍然具有挑战性。 在 NSDI 2012 上对与会者的非正式调查中,我们发现很少有人对 Paxos 感到满意,即使是经验丰富的研究人员也是如此。 在阅读了一些简化的说明并设计了我们自己的替代协议后,我们才了解完整的协议,这一过程耗时近一年。
We hypothesize that Paxos’ opaqueness derives fromits choice of the single-decree subset as its foundation.Single-decree Paxos is dense and subtle: it is divided intotwo stages that do not have simple intuitive explanationsand cannot be understood independently. Because of this,it is difficult to develop intuitions about why the single-decree protocol works. The composition rules for multi-Paxos add significant additional complexity and subtlety.We believe that the overall problem of reaching consensuson multiple decisions (i.e., a log instead of a single entry)can be decomposed in other ways that are more direct andobvious. 我们假设 Paxos 的不透明性源于它对单法则子集的选择的基础。单法则 Paxos 是密集而微妙的:它分为两个阶段,没有简单的直观解释,无法独立理解。 因此,难以理解单法令协议为何起作用的直觉。 多 Paxos 的组成规则增加了许多额外的复杂性和微妙之处。我们认为,可以通过其他更直接和明显的方式来分解在多个决策(即对数而不是单个条目)上达成共识的总体问题。
The second problem with Paxos is that it does not pro-vide a good foundation for building practical implemen-tations. One reason is that there is no widely agreed-upon algorithm for multi-Paxos. Lamport s descriptionsare mostly about single-decree Paxos; he sketched possi-ble approaches to multi-Paxos, but many details are miss-ing. There have been several attempts to flesh out and op-timize Paxos, such as [26], [39], and [13], but these differ2 from each other and from Lamport s sketches.Systems such as Chubby [4] have implemented Paxos-like algo-rithms, but in most cases their details have not been pub-lished. Paxos 的第二个问题是,它没有为构建实际实现提供良好的基础。一个原因是,对于 multi-Paxos,还没有得到广泛认可的算法。Lamport 的描述大多是关于单一法令的 Paxos;他概述了多 paxos 可能的方法,但是很多细节都被遗漏了。已经有一些尝试来充实和调整 Paxos,如[26]、[39]和[13],但它们彼此不同,也不同于 Lamport 的草图。像 Chubby[4]这样的系统已经实现了类似 paxos 的算法,但它们的很多细节还没有公开。
single-decree decomposition 的另一个结果是 Paxos 难以用于构建实际系统。详细解释还是看文章吧。
因此,实际系统与 Paxos 几乎没有相似之处,都从 Paxos 开始,讲述实现的困难,然后发展出完全不同的体系结构。Chubby 的实现者对 Paxos 的评价很典型:
There are significant gaps between the description ofthe Paxos algorithm and the needs of a real-worldsystem. . . . the final system will be based on an un-proven protocol
Designing for understandability
在 Raft 设计过程中存在许多要做取舍的点,取舍基于可理解性。设计者总是在想如何能使读者完全理解设计方法和实现。
这种“方便理解”的设计是主观的,不过提出了两种普遍使用的技术:过程拆解、简化状态机状态。
The Raft consensus algorithm
算法主体部分。
图 2(也就是 6.824 课程教授提到的要特别注意的图)提供了简化版算法以供参考。
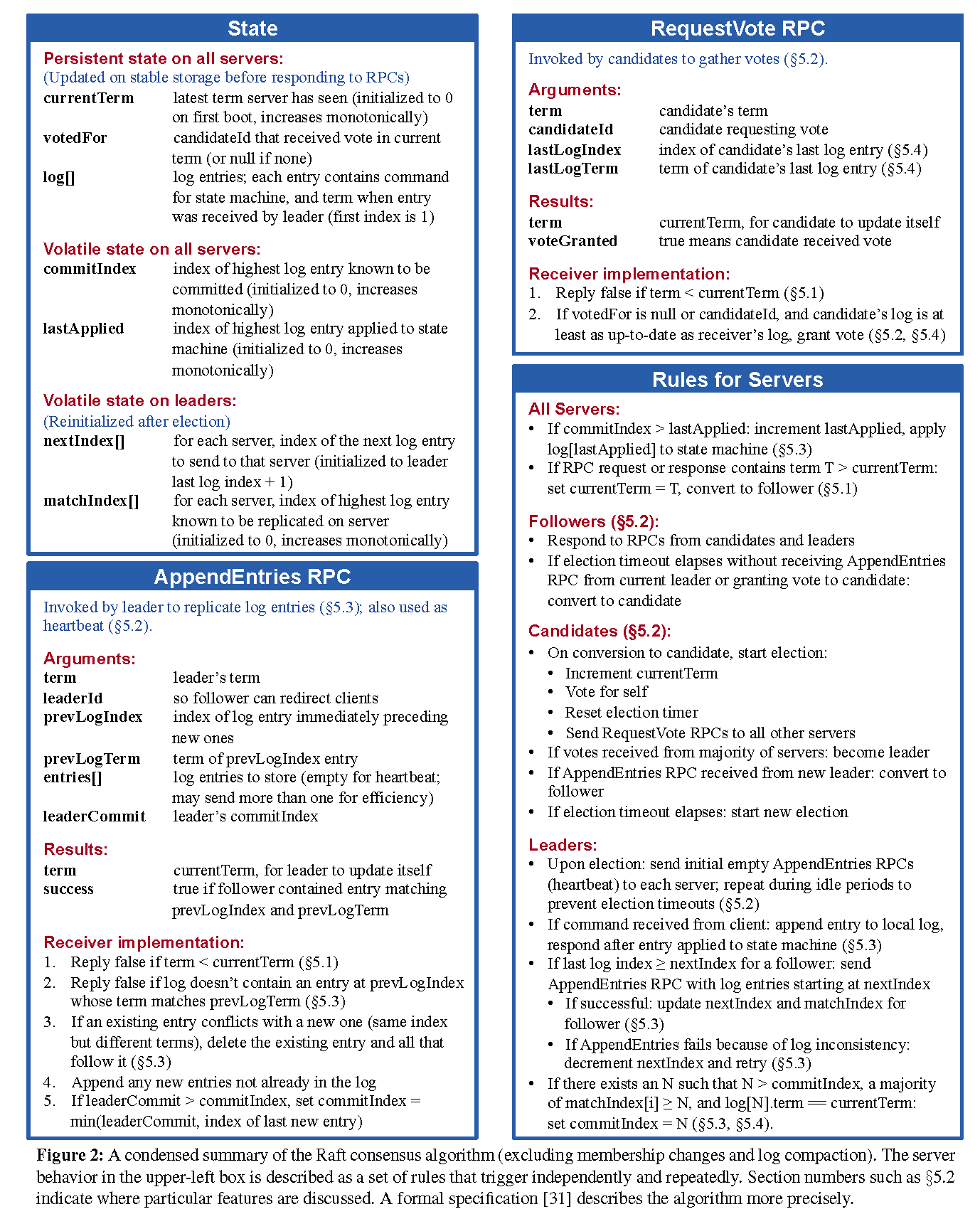
图 3 列出了算法的核心性质。

文章拆分成四个模块来介绍
Step 2 阅读中着重理解一下各部分的介绍,对 Safety 证明部分粗略浏览下,放在 Step 3 中进一步阅读。
Raft basics
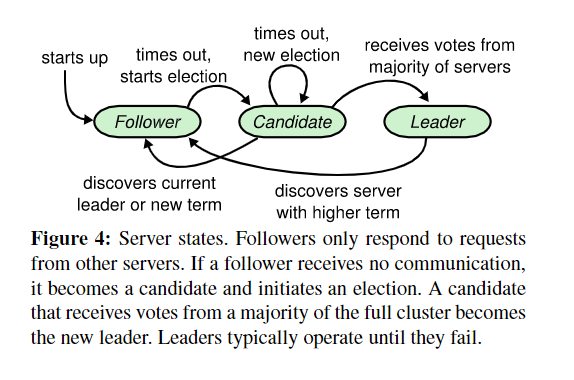
每个 server 的三种状态:leader,follower,candidate。系统保证正常情况下只有一个 Leader,在这个架构下。Leader is strong and followers are passive.。Leader 负责处理所有客户端请求并展开 replication,而 follower 不会自发启动任何请求,只会被动应答 candidate 和 leader。Candidate(候选者)是用来进行 leader 选举时的状态。如图 4 所示。
Raft 将时间划分为不同长短的 term(任期),用连续整数来标识,每届任期都从一次选举开始。若选票分裂,没有选出 leader,则任期以无 leader 情况结束,并且会在稍后启动新的一轮选举(random time)。如图 5 所示。
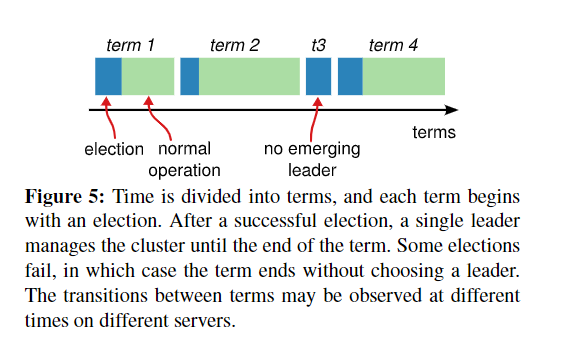
在一些情况下(比如网络中断、延迟、隔离),server 可能会观察不到选举过程甚至整个任期。Term 在 Raft 中像一个逻辑时钟(没错,Lamport 他又来了)。currentTerm在每台机器上都会被持久化维护。服务器间的交流(比如选举信息或是指令执行),类似 Lamport 逻辑时钟的事件(自增原则要看后面的实现细节)。如果一个服务器的 currentterm 比另一个服务器的 currentterm 小,那么它将其 currentterm 更新为更大的值。如果一个候选人或领导发现他的任期已经过期,它立即恢复到 follower 状态。如果服务器收到一个过去任期的请求,它将拒绝该请求。
Raft 机器间交流通过 RPC 实现,仅需要两种类型的 RPC,后续章节添加了一种 RPC 用来传递快照。
- RequestVote PRCs:由 candidates 发起用于选举(在 Leader election 一节中着重介绍)。
- AppendEntries RPCs:由 leaders 发起,以 heartbeat 形式提供 replicate log 的功能。
Leader election
主体过程描述如下
- 以 follower 身份启动,如果能持续收到来自 candidate 和 leader 的消息,follower 身份会维持。
- 在丢失通信达到一定时间(election timeout)后,follower 会开始启动一次选举。
- follower 增加它的 currentTerm 值并转换到 candidate 状态。
- 为自己投票同时并行启动 RequestVote RPCs 访问集群内其他机器。
- candidate 维持其身份直至
- 赢得选举
- 得到 majority 的选票
- 转换为 leader 身份并开始发送心跳线信息
- 其他机器赢得选举
- 比较 AppendEntries RPC 中 term 与 currentTerm 的大小,RPC 中任期大于等于自身任期,则转变为 follower。
- 否则拒绝 RPC 请求,保持 candidate 身份。
- 一段时间后发现没有人赢得选举
- 多个 candidate 发起选举导致选票分裂无人当选
- 每个 candidate 经过一小段时间后重启选举
- 没有其他措施保证时,选票分裂可能重复。(改进:再下次选举前加入 150-300ms 的随机延时)
- 从可理解性角度抉择:设计者对算法进行了多次调整、包括 rank candidate 形式,每次调整后都会出现新的情况。最后得到的结论,随机重试的方法更明显和可理解。
- 赢得选举
Log replication
图 6 显示日志的组织情况。
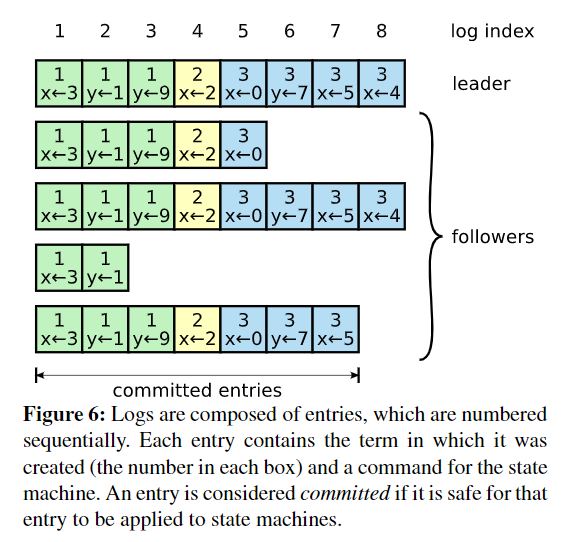
- 选出 leader 后,leader 与客户端进行通信,接受并反馈客户端请求。
- leader 持续向其他机器并行发送 AppendEntries RPCs,维持身份同时拷贝 entry(但不执行)。
- leader 决定什么时间可以commited entry(提交),即使集群机器可以执行 entry。
- 条件:当 leader 创建的 entry 被 replicated 到绝对多数的机器。
- leader 持续跟踪要进行 commit(已经建立好)的最大的 log index,并将该索引包含在后续的 AppendEntries RPCs 中,以便其他机器最终发现。
- follower 获知 entry 被 commited,便在本地执行该日志。
Raft 保持下面的重要性质,他们共同构成图 3 的(Log Matching):
- 两份日志中的 entry 块,若具有相同的 log index 和 term,则储存相同命令。
- 两份日志中的 entry 块,若具有相同的 log index 和 term,则在之前的日志记录都是相同的。
正常情况下,leader 和 follower 间的日志都是一致的,但是如果发生 crash,会出现各种不一致的情况(多出未 commit 的 entry 块、缺少块、历史块产生冲突)。
在 Raft 中,leader 强迫 follower 遵循自己的日志记录,也即冲突覆盖。 后面 Safty 小节将说明,再加上一个限制条件,这是安全的。
为了进行覆盖,leader 需要找到和 follower 达成一致的最近 entry,并删除之后所有的 entries。leader 未每个 follower 维护一个nextIndex,标明下一个该传送的 log entry。当一个 leader 刚被选举上台时,他初始化全部 follower 的nextIndex为 leader 最后一个 log+1。如果 follower 与 leader 的日志不一致,AppendEntries RPC 中的一致性检查失败,然后 leader 递减nextIndex的值再次发送 AppendEntries RPC 请求,直至找到能 match 的日志位置。然后如上述,删除后递增nextIndex持续进行请求。
优化 AppendEntries 交互的方法
当 AppendEntries 失败时,follower 可以知道冲突块所在的 term,以及该 term 第一个块。这样
nextIndex一次可以减去该 term 冲突块的数。(作者质疑这种优化的必要性,理由是 failure 并非那么频繁,不会出现大量需要小步修正的 entries)
这种 log replication 机制,对于新选出的 leader,无需额外操作既可以保证集群中日志记录逐渐收敛,并且满足 leader 不重写自己日志的性质。同时只要绝对多数的机器正常运转,一轮 RPCs 就可以将新的 entry 复制到机器上,少数故障不会影响系统表现。
Safety
到目前为止所描述的机制还不足以确保每个状态机以同样的顺序执行完全相同的命令,增加一些限制。
选举限制
个人理解:鸽巢定理的应用
Raft 使用一个简单的机制保证先前任期 leader 的所有 commited entries 会存在在新选举的 leader 上。这样就保证了日志流是单向的(leader 到 followers)。
一个 entry 想要被 commited 要得到majority的机器的回应,而一个 candidate 必须联系集群中的majority才能当选,根据鸽巢定理,每条 commited entry 必须至少出现在 candidate 联系的机器中的一台上,如下图所示。
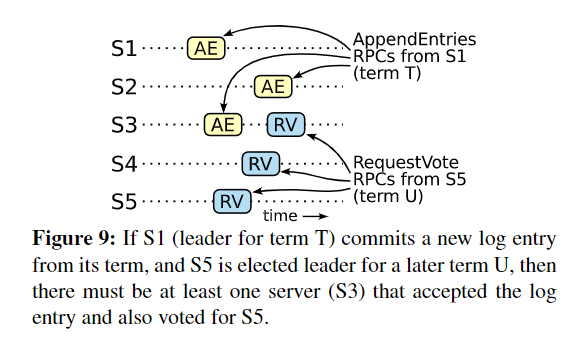
Raft_6 Raft 按如下方式定义日志的新旧:
- 不同 term,则越后面的 term 越新(逻辑时钟)
- 相同 term,越长的 log 越新
提交先前任期的 entry
对于前一任期 replicate 但是未 commit 的 entry,现在任期的新 leader 在继续 replicate 时无法第一时间意识到达到绝对多数(从而有可能延迟或者忽略到该 commit 的 entry,而被后续任期的 entry 覆盖),如下图所示。

Raft_7 Raft 要求 leader 在 replicate 先前任期中的 entry 时,保留其原有的 term(在其他一些共识算法中,leader 必须使用新的 term 编号来进行复制。)为了避免图中的问题,Raft不会根据副本计数来提交过去任期的 entry,只会根据计数提交当前任期内的 entry。(交现在不交过去)
安全性争论
反证法证明 Leader Completeness Property
过程 Pass,见第三部分。
根据 Leader Completeness Property,可以证明 State Machine Property。
证明 Pass,见第三部分。
Follower and candidate crashes
先前讨论的是 leader 出状况,实际上 follower 和 candidate 的崩溃情况要简单些。
- follower 或 candidate 崩溃,leader 持续发送 AppendEntries RPCs
- 重连时 RPC 会连通
- 若 follower 或 candidate 接受到 RPC 但是在返回结果前崩溃,那么重连时会收到相同的 RPC,因为 Raft RPC 是幂等的,所以无影响。
Timing and availablility
Raft 设计要求,系统安全性不依赖于时间,不会因事件过快/过慢导致错误结果。但还是有些地方肯定存在时间限制。
Leader election 过程时间要求。
\[broadcastTime \ll electionTimeout \ll MTBF\]
- broadcastTime:并行发送 RPCs 到各个机器并收到回复的平均时间。
- electionTimeout:前面描述的判定一轮选举的 timeout
- MTBF:单个机器故障间隙的平均时间。
分析,Pass,详情见第三节。大致理解,不能太频繁重设 leader,但又要保证真正故障时系统不会长时间停滞。
问题记录
未读(且值得读)文献记录
The Part-Time Parliament ── Lamport 于 1998 年发表在 ACM Transactions on Computer Systems 注:这是该算法第一次公开发表。
Paxos made simple 注:Lamport 觉得同行无法接受他的幽默感,于是用容易接受的方法重新表述了一遍。
Step 3
思路复现
证明与推理复现
实验验证复现
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!