多媒体原理与系统——期末复习知识点汇总
绪论
前言研究方向
- 图象语义分析
- 语音识别和合成
- 多摄像机视频协同系统
- 图象视频合成
- 对象视频和成
- 对象检测跟踪
- 图象视频检索
- 新型音视频编解码技术
- 沉浸式显示关键技术(VR 虚拟空间、AR 真实与虚拟互动)
- 多媒体内容和传输安全
数字音频基础
主要,参考手写笔记章节这里先不细致复习。
将模拟音频转换成数字音频
留意 PCM,DM,ADPCM,自适应差分脉冲编码调制 ADPCM 的步骤。
音频格式文件
CD-Audio、WAVE、MPEG Audio 家族、MIDI(描述一系列指令而非音乐本出身)、WMA
音频压缩的原理
编程环境与平台
COM 组件与应用
组件:组件(或软件组件)是指构建软件系统的基础性单元或模块,它封装了特定的设计策略,通过标准化、可重用和开放的接口与其它组件进行组合,以便构建完整的应用系统。
- 可扩展性:可以方便的将应用系统扩展到网络环境下
- 跨平台性:与语言和平台无关的特性使所有的程序员均可充分发挥自己的才智和专长编写组件模块。
COM 组件对象和接口
多媒体应用设计的主要特点
- 流数据,数据量大,存储和传输的高效性
- 音频流
- 视频流
- 实时性:视频跟踪;不能做迟来大师
- 同步性
- 视频与音频的同步
- 字幕与图象的同步
- 自适应性和鲁棒性
- 数据格式复杂
- 应用环境复杂(终端设备型号多、失效情况等)
Microsoft Media Foundation
MF 介绍相关
基本组成元素概念和用途、MF 的编程模式、数据管道模式
波形文件分析
波形音频文件的概念
波形音频文件是存储数字音频样本(samples)序列的格式文件,这些样本直接记录了音频的波形,故称波形音频文件。波形音频文件为音频数据处理提供了最基本的数据源。MIDI 音频和 MP3 等各类压缩格式的音频文件最终都要转换成波形音频才能应用。
WAVE 文件结构
WAVE 文件是使用最广泛的声波音频文件,它遵从 RIFF(ResourceInterchangeFileFormat)格式标准。WAVE 文件的头四个字节是“RIFF”。WAVE 文件由若干个块(Chunk)组成。按照在文件中出现的先后顺序,一般有四个块,即 RIFF WAVE Chunk,Format Chunk,Fact Chunk(可选),Data Chunk。
详细文件结构参见 PPT,需要注意的是,RIFF WAVE Chunk 中的 Size 是 FileLeb-8。Data Chunk 中的 Size 是真正数据部分的 Size。
无损数据(编码)压缩算法
这部分有手写笔记
数据(编码)压缩基础
- 编码:将携带信息的一种符号序列按照一定规则映射成另一种符号序列的变换。根据信源的统计特性进行。
- 目的:去冗余,压缩信源剩余度,提高传输消息的有效性,把消息变成适合信道传输的信号。
- 分类:有损编码、无损编码
- 数学模型:见 PPT
熵编码讲解
算术编码讲解
行程编码讲解
数字图象基础
数字图像基本概念
图像
时空中各个坐标点的颜色值(强度)集合。
- 3 维动态图像 \(I= f(x,y,z,t)\)
- 3 维度静止图像 \(I = f(x,y,z)\)
- 2 维动态图像\(I = f(x,y,t)\)
- 2 维静止图像 \(I = f(x,y)\)
数字图像
如何从图像到数字图像?
从图像到数字图像
- 采样(扫描),行采样+列采样
- 图像分辨率(resolution):正式用法:单位面积或长度上像素的个数。习惯用法:图像在水平和垂直方向上的像素数的乘积。
- 上采样(提高分辨率,放大图像,从而可以显示在更高分辨率的显示设备上。)
- 下采样(缩小图像大小)。
- 量化:像素的位深度,量化等级越多,图像层次越丰富,图像质量好,但数据量大;量化等级越少。
- 采样(扫描),行采样+列采样
- 颜色
亮度
指色光的明暗程度,由色光所含的能量决定。光源色光的亮度正比于它的光通量(光功率);物体色光的亮度正比于各点反射光的光通量,由光源亮度和物体光反射能力共同决定。
色调
指颜色的类别,如通常所说的红色、绿色、蓝色、品红、青色等色调。光源的色调由其光谱分布(光频率)决定;物体的色调由照射光源的光谱和物体本身反射特性共同决定。(例如蓝布在日光照射下,只反射蓝光而吸收其它成分。如果分别在红光,黄光或绿光的照射下,它会呈现黑色。)
饱和度
指色调的深浅程度。各种单色光饱和度最高。单色光中掺入的白光愈多,饱和度愈低,白光占绝大部分时,饱和度接近于零,白光的饱和度等于零。物体色调的饱和度决定于该物体表面反射光谱辐射的选择性程度,物体对光谱某一较窄波段(颜色)的反射率越高,而对其它波长的反射率越低或不反射,则物体的该颜色饱和度就越高。
色彩模型
RGB 模型
用红、绿、蓝三种基本颜色表示其他颜色的模型。红、绿、蓝原色是加性原色,不同量原色混合在一起可以产生不同的复合颜色。
RGBA 模型
在 RGB 的扩展;增加一个 Alpha 通道,表示透明度。如果一个颜色值的 Alpha 通道值为 0,则该颜色是完全透明的(该颜色看不见);Alpha 通道值为 1,则该颜色完全不透明(只看到该颜色),这个时候 RGBA 退化为 RGB。
CMY 空间和 CMYK 模型
- 是用物质吸收光的数量(反射)表示色彩的方式,即通过青(C)、品红(M)、黄(Y)三原色颜料混合表示颜色,称为 CMY 颜色空间。理论上 CMY 空间中,混合青(C)、品(M)、黄(Y)三原色时理论上会得到黑色;实际应用由于工艺问题是暗红色,所以额外引入纯黑(K,不是 B!),得到 CMYK 模型,应用于实际的印刷工业。
- 对比 RGB 模型:RGB 中,当红、绿、蓝三原色混合时,产生白色,这种叫加色模型。青、品、黄混合时,产生黑色,这种叫减色模型。
- 一般电脑屏(光源)RGB 模型;印刷品(反射源)CMYK 模型
像素色彩格式
- 二值图像与灰度图像
- 彩色图像
- 真彩图像
- 伪彩图像
数字图象存储方式
- 真彩图像像素的存储格式
- RGB888 BGR(低地址->高地址)
- RGB8888 BGRX(X 为保留或表示透明度,低地址->高地址)
BMP 图像格式
GIF 图像格式
JPEG 图像压缩技术
基于正交余弦变换(FDCT)的有损压缩模型
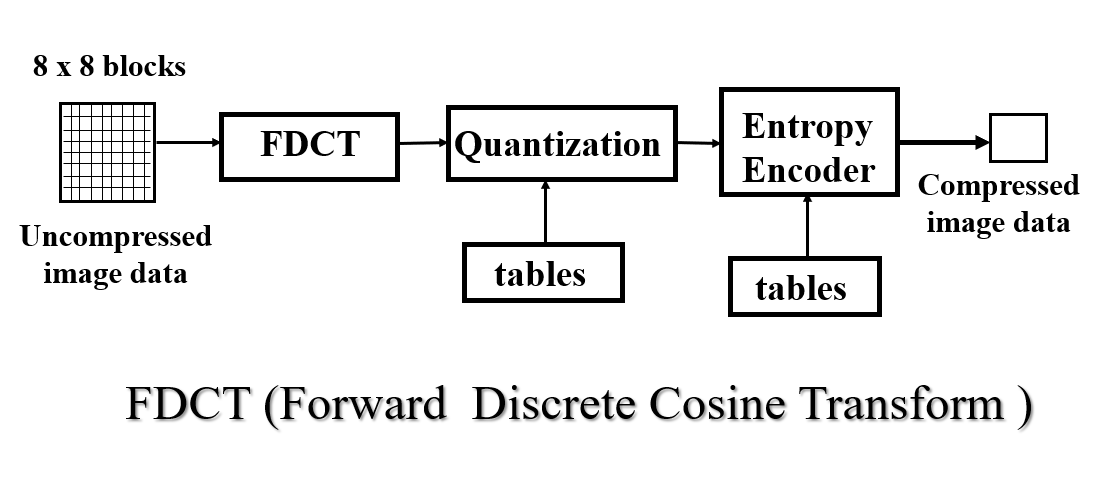
JPEG_1 DCT 也是空间域到频率域的转换,左上角低频,右下角高频,实现能量的集中。
\[F(u,v) = \frac{1}{4}C(u)C(v)[ \sum_{i=0}^{7}\sum_{j=0}^{7}f(i,j) \cos \frac{(2i+1)u\pi}{16} \cos \frac{(2j+1)v\pi}{16}]\]
从这个式子我们容易发现,当\(u=v=0\)时,\(C(u),C(v) = \frac{1}{\sqrt{2}}\),得到的\(F(0,0)\)实际为原空间域均值乘以边长(这里是 8),老师补充,\(F(0,0)\)与空间边长乘正比(比如 4x4,得到的应该是均值的 4 倍)。
- DCT 的作用:DCT 的作用: DCT 变换将空域图像(即由颜色像素值构成的平面空间)转换到频域表示的图像,从而把能量集中在低频系数上。DC 值和像素块均值成正比
量化:通过除法和舍入操作,丢弃一些高频信息。
\[F'(u,v) = Integer(Round ( F(u,v) /Q(u,v)))\]
老师谈:设置量化步长时,低频的 DC 系数一般不丢,优先丢表示细节的高频分量,所以见右侧。
量化表:亮度量化表和色差量化表,即描述\(Q(u,v)\)(色差右下角好多 99,亮度相对于来说分散一些,这两个表是经验表)。
量化即 JPEG 压缩过程中,有损的部分。
直流系数的编码:采用差分编码;数据块之间去冗余,相邻数据块相似,像素均值差值不大,DC 值差值不大。(DC 用差分)
- 交流系数的编码:基于 Z 字形扫描的行程编码,扫描从右下一条龙到左上。(AC 用行程编码)
最后,对前面生成的数据流进行无损压缩编码(哈夫曼或算术编码)。
图像处理与应用程序设计
主要目标:
- 认识与图像显示和处理有关的 API
- 掌握基于 win32 GDI 的图像显示方法
- 掌握基于 win32 GDI 的图像数据访问方法
- 能够实现简单的图像处理功能
- 能够实现滤波
- 能够动画效果
- 能够在 win32 api 中调用第三方图像处理库
与图像显示和处理有关的 API
应用程序域 Win32 API 中间层:GDI、Direct2D... OpenCV、Dlib
OpenCV 和 Dlib 是跨平台的图像处理函数库
基于 win32 GDI 的图像显示方法
教材中的方法
- 用 LoadImage 函数载入图像(只能读取 bmp,ico 等格式,常用的 jpeg 不支持)
- 用 GetObject 函数获得图像的基本信息(如长宽、位深等)
- 用 GlobalAlloc 和 GlobalLock 函数创建一个缓存用来保存图像数据
- 用 GetDIBits 函数把图像数据保存到刚才创建的缓存里
- 用 SetDIBitsToDevice 函数显示缓存中的图像
另一个方法(实验代码中使用)
- 用 LoadImage 函数载入图像
- 用 GetObject 函数获得图像的基本信息(如长款、位深等)
- 用 CreateCompatibleDC 和 SelectBitmap 函数创建一个内存绘图句柄并跟新图像绑定
- 使用 BitBlt 函数显示内存绘图句柄所关联的图像
基于 win32 GDI 的图像数据访问方法
教材中的方法
- 方法 1:用 GetPixel 和 SetPixel 函数来对绘图句柄所关联的图像进行访问,可以直接访问单个像素的值。
- 方法 1 的优点是直观,缺点是慢。
补充学习:GetPixel 和 SetPixel 非常慢,老师猜测是由于 GetPixel 和 SetPixel 中设计很多转换(早期索引色彩等)。速度 30s 与实验代码中(1s 不到)差别巨大。
另一方法 2
- 方法 2:用 GlobalLock 函数所返回的缓存区指针来直接访问像素值。
- 方法 2 的优点是快,缺点是不够直观。
方法 3(实验代码中使用)
- 通过 CopyImage 函数结合 LR_CREATEDIBSECTION 参数,获得包含了数据指针新图像
- 通过 GetObject 函数获得新图像的基本信息结构体(除长宽、位深等信息外,还包含可用的数据指针)
- 通过基本信息结构体中的数据指针来访问像素值
实现简单的图像处理功能
Pass
数字视频基础
视频概述
一些基本概念
- 视频(Video)是指随时间动态变化的一组图像。一幅图像在视频中称为一帧,帧是构成动态图像的基本单元。
- 帧:是指组成影片的每一幅静态画面。通常我们看到的电视、电影或其他视频节目,其实是由一系列的静态图像画面构成的,相邻图像的画面之间差别很小,将这些连续的画面高速播放,由于人眼视觉的暂留特性,所以感觉图像是动态的且运动流畅,这些连续图像的每一幅就被称之为一帧。
- 帧高宽比:是指影片画面图像的高度和宽度比例。常见的电视格式为标准(标清)的 4:3 或 1.33 和宽屏(高清)的 16:9 或 1.78。
- 帧频:是指播放视频时每秒钟所播放的画面数量。电影是每秒 24 帧,PAL 制式的影片是每秒 25 帧,NTSC 制式是每秒 29.97 帧。
- 扫描方式:分逐行扫描或隔行扫描。若采用隔行扫描,则先扫描奇数行,再扫描偶数行,因此每幅图像需扫描两次才能完成。
- 场:电视机因受信号宽带限制,以隔行扫描的方式显示图像,通过两次扫描来交错显示奇数行和偶数行,每扫描一次叫做一“场”,两个场合并成一帧。
- 场频:每秒扫描的场数。在进行隔行扫描时,场频是帧频的两倍。
模拟视频(电视)
注意消隐信号。

电视的彩色模型:YUV 模型、YIQ 模型、YCbCr 模型
YIQ 模型与 YUV 模型类似,YIQ 颜色空间中的 I 和 Q 分量相当于将 YUV 空间中的 UV 分量做了一个 33 度的旋转。
- 复合电视信号(Composite signal)
- RGB/YUV/YIQ 的所有分量一起被编码成一个信号。
- 行周期:64us
- 信号:52.2us
- 行消隐:11.8us ;前肩 1.3us;行同步 4.7us;后肩 5.8us;彩色和黑白电视的主要区别
- 分量电视信号(Seperated signal)
- RGB/YUV/YIQ 的每一个分量分别被编码成一个信号。
- S-Video 信号
- 亮度信息被编码成一个信号,两个色差编码成一个复合信号。
- 为什么电视系统要采用 YUV(YIQ)彩色模型
- 彩色电视信号能兼容黑白电视
- 有利于区分编码 Y 信号与 UV 信号
模拟视频的数字化
复合信号-信号分离-A/D 转换器-数字视频信号
数字视频的存储格式
视频应用程序设计
未加入章节标题
数字视频编码原理与标准
数字视频编码的基本原理
- 数字视频的冗余性:
- 空间冗余(帧内冗余):一帧视频内部,相邻像素的颜色值近似,这成为帧内冗余。
- 时间冗余(帧间冗余):相邻帧的内容大部分相同。
- 统计冗余:如 1,0,0,0,0,0...
- 感知冗余:依赖人眼视觉的敏感程度。不敏感的就可以认为是感知冗余
- 数字视频编码类型
- 帧内编码:利用图像内部的相关性进行压缩,空间冗余压缩。
- 帧间编码:利用相邻图像帧之间的相关性进行压缩,时间冗余压缩。
- 数字视频编码的基本思想:
- 空间冗余压缩:主要在帧内编码中理解;
- 时间冗余压缩:主要在帧间编码中理解;
- 统计冗余压缩:熵编码;
- 感知冗余:量化步长体现
视频帧的分类
- I 帧:(关键帧?)是利用图像内部的相关性进行压缩的图像帧,即帧内编码图像,数目少
- P 帧:是指对其施加单向预测编码的图像,数目多
- B 帧:是指对其施加双向预测编码的图像,数目多
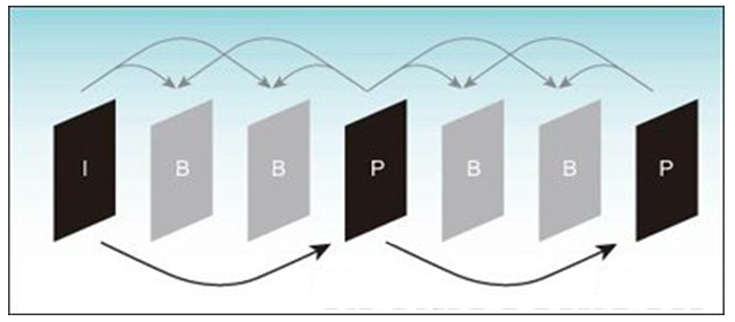
VideoEncode_1 - 视频编码的核心思想:预测+残差
- 对于相关的视频图像,发送端不需要把每帧图像上所有的像素值都传送给接收端:
- 图像内:记录基准像素(预测像素)和像素残差;根据变化内容和预测像素可以还原当前像素。
- 图像间:不同图像帧的残差,和前一帧图像(预测图像)的内容来恢复当前帧图像,
- 这就比全部传送每帧图像的具体细节所需的数据量要小得多。WHY?(个人理解:补丁和原像关系一样,储存残差要比储存原始图像,表示所需空间少,存储空间少)
帧内编码
帧内编码(无预测)
类似 HPEG 图像压缩,图像分块:4*4;8*8; 16*16 (宏块)
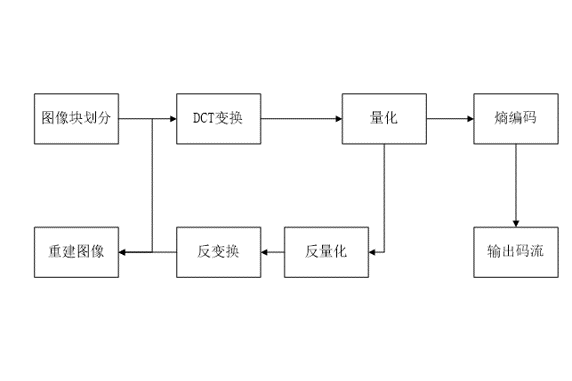
帧内编码(有预测)
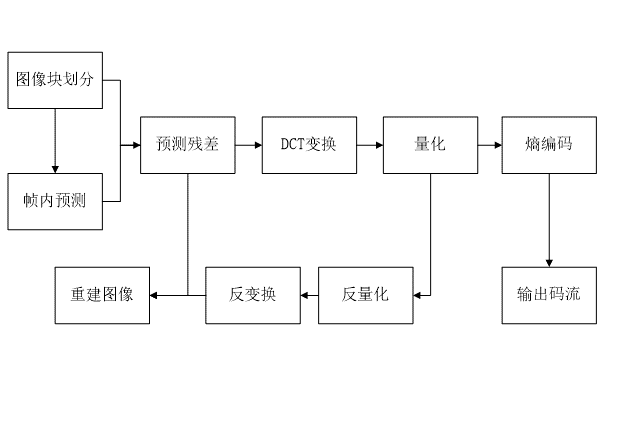
帧内预测编码
帧内预测编码:是指利用视频空间域的相关性,使用当前图像已编码的像素来预测当前像素,以达到去除视频空间冗余的目的。
设当前像素值为,是其水平和垂直位置的坐标,进行帧内预测得到的像素值为计算如下:
\[\hat{f}(x,y) = \sum_{(k,l) \in Z} a_{k,l} \hat{f}(k,l)\]
其中 \(a_{k,l}\)是二维预测系数, \(Z\)是参考像素所在的区域,\((k,l)\)是参考像素的坐标。
H.264 一共规定了 3 种大小的亮度帧内预测块:4×4、8×8 及 16×16。其中 4×4 和 8×8 块包含 9 种预测模式,16×16 块包含 4 种预测模式。下面简要介绍几种预测模式,其他预测模式的计算可以参考书籍:
新一代高效视频编码 H.265HEVC 原理、标准与实现 [万帅,杨付正 编著] 2014 年版
4x4 的 9 种预测模式
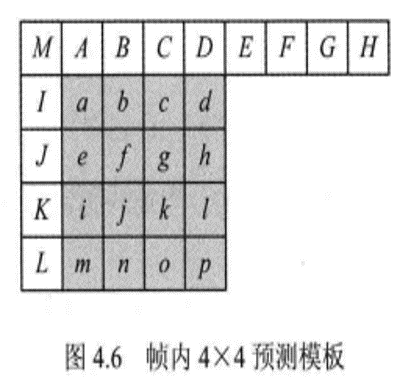
VideoEncode_4 - 垂直模式(Vertical Mode 0):\(\hat{f} = B\)
- 水平模式(Horizontal Mode 1):\(\hat{f} = J\)
- DC 模式(DC Mode 2):\(\hat{f} = (A+B+C+D+I+J+K+L+4) \gg 3\)
- 左下对角线模式(Diagonal-Down-Left Mode 3):\(\hat{f} = (C+2D+E+2) \gg 2\)
- 右下对角线模式(Diagonal-Down-Right Mode 4):\(\hat{f} = (I+2M+A+2) \gg 2\)
- 垂直向右模式(Vertical-Right Mode 5):\(\hat{f} = (M+2A+B+2) \gg 2\)
- 水平向下模式(Horizontal-Down Mode 6):\(\hat{f} = (M+2I+J+2) \gg 2\)
- 垂直向左模式(Vertical-Left Mode 7):\(\hat{f} = (B+2C+D+2) \gg 2\)
- 水平向上模式(Vertical-Right Mode 8):\(\hat{f} = (J+2K+L+2) \gg 2\)
- 16x16 的 4 种预测模式
- 垂直模式
- 水平模式
- DC 模式(平均值)
- Plane 模式(平面)
最优预测模式
在 H.264 帧内编码中,采用了率失真优化(RDO)技术来选取最佳的帧内预测模式:
通过遍历所有预测模式,寻找率失真代价 RDCost 最小的作为最优预测模式,
率失真代价公式为
\[RDCost=SSD+\lambda \times Rate\]
SSD 表示当前块与重建块的平方差之和,λ 为量化参数 QP 的函数;Rate 表示熵编码后的码率。
帧间编码
基本计算框架
- P 帧的编码:在参考图像(帧内编码的重建图像)中搜索出与编码图像宏块最相似的宏块(又称最佳匹配宏块),接着计算两者的残差,然后对残差进行 DCT 运算,接着对结果量化和熵编码
- B 帧的编码:双向预测计算与单向预测计算类似,区别在于一个编码图像有前后两个参考图像,算法分别在两个参考图像中搜索出两个最佳匹配宏块(因此得到两个运动向量),接着求这两个匹配宏块的平均值,然后用这个平均值与编码图像块进行差分运算,之后是 DCT 变换、量化,RLE 编码和 Huffman 编码。
- 解码过程:也是逐块进行的,首先是 Huffman 解码并分离出运动向量,根据运动向量,然后在参考图像(先解码)中得到最佳匹配宏块。接着是行程解码,反量化和反向正交余弦变换,得到差分值(残差),最后把残差补充上去(叠加),即解码出一个宏块。双向预测解码则类似。
- 运动估计:在参考图像中搜索出最佳匹配宏块的计算过程称为运动估计(Motion Estimation,ME),而参考图像中最佳匹配宏块相对于编码图像宏块基准位置的偏移量(水平方向的为 Δx,垂直方向上为 Δy),称为运动向量(Motion Vector,MV)。运动向量要参与编码。
- 运动补偿:根据运动向量将差分值补充到参考图像匹配宏块中去的过程称为运动补偿(Motion Compensation,MC)
匹配度计算
绝对差(和)(Sum of Absolute Difference)
\[SAD= \sum_{i=0}^{15}\sum_{j=0}^{15} | f(i,j) - g(i-d_x,j-d_y) |\]
均方差(均)(Mean of Square Error)
\[MSE = \frac{1}{M \times N} \sum_{i=0}^{15}\sum_{j=0}^{15} \big[ f(i,j) - g(i-d_x,j-d_y) \big]\]
平均绝对差(均)(Mean of Absolute Difference)
\[MAD= \frac{1}{M \times N} \sum_{i=0}^{15}\sum_{j=0}^{15} | f(i,j) - g(i-d_x,j-d_y) |\]
运动搜索算法
全搜索法
在参考图像中,以宏块为单位,每次错位一个像素,从起始点出发,遍历整个参考图像。计算量最大,速度最慢,最精准(全部枚举)。
二维对数搜索法
一轮搜索中,如果 MSE 值最小点出现在边缘 4 个点中的一个位置,则以该点作为新的中心点,保持步长不变,开始新一轮的十字形分布的 5 点搜索。如果 MSE 值最小点出现在中心点,则保持中心点位置不变,将搜索步长减半,重新构成十字形点群,继续搜索这 5 个点。
若发现新的十字形点群的中心点位于搜索区的图像边缘,则步长减半,并搜索周围 8 个点(图像内),MSE 值最小点为中心点,继续搜索。
如果该次搜索步长已经为 1,搜索的 MSE 值最小点所在位置即为最佳匹配宏块位置,停止搜素,其偏移量即为运动向量。
三步搜索法
在参考图像中,以宏块为单位,每次错位 n 个像素,从起始点出发,搜索东西南北东南西南西北东北 8 个方向,选择其中 MAD 最小者重复搜索,三次,但搜索距离减半。(距离分别为 3、2、1)
搜索起点的选择
- 以参考帧对应的(0,0)位置为起点: 无须计算简单, 没有利用视频本身信息,易于陷入局部最优点。 没有对运动矢量进行预测,无法使用残差
预测起点位置
利用相邻块之间和相邻帧之间具有很强的相关性,对初始搜索点进行预测计算。
- 基于 SAD(Sum of Absolute Difference)值的起点预测方法。该方法分别求出当前块与其相邻块间的 SAD 值,然后选取 SAD 最小的块的运动矢量作为预测值。记录运动矢量的预测值和实际运动矢量的残差。该方法预测精度高,但计算 SAD 值的时间开销大
- 利用相邻块和相邻帧对应块的运动矢量来预测当前块的搜索起点。H. 263 使用了 3 个相邻块的运动矢量的中值作为当前块运动矢量的预测值。记录运动矢量的预测值和实际运动矢量的残差。该方法计算时间开销小,预测精度相对低于第一种
- 方法 1,2 结合,基于相邻运动矢量相等的起点预测方法。如果当前块的各相邻块的运动矢量相等,则以其作为当前块运动矢量的预测值;否则,求出当前块与其相邻块间的 SAD 值,然后选取 SAD 最小的块作为预测起点。记录运动矢量的预测值和实际运动矢量的残差。
国际视频编码标准
MPRG 系列
而由 ISO 和 IEC(国际电工委员会)的共同委员会中的 MPEG 组织(Moving Picture Expert Group)制定的标准。主要针对视频数据的存储应用,也可应用于视频传输,如 VCD、DVD、广播电视和流媒体等,它们以 MEPG-x 命名,如 MEPG-1、MEPG-2 和 MEPG-4 等。
H.26x 系列
H.26x 系列由 ITU 组织制定的标准。主要是针对实时视频通讯的应用,如视频会议和可视电话等,它们以 H.26x 命名,如 H.261、H.262、H.263 和 H.264 等。
H.261 编码器
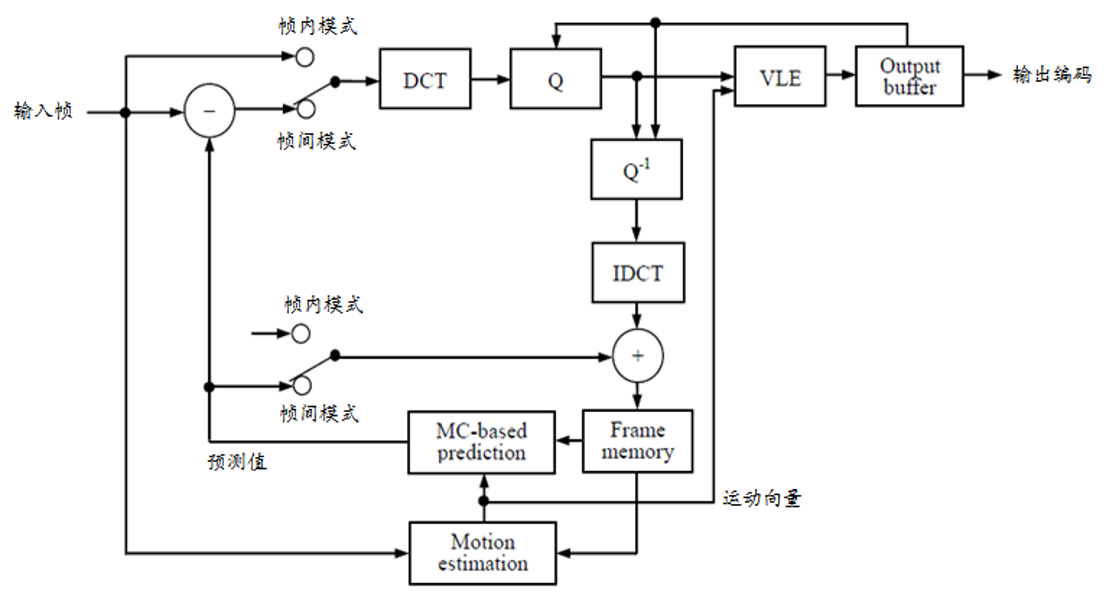
H.261 H.263 编码器 H.263 与 H.261 的编码原理基本相同,但是,H.263 在 H.261 的基础上做了很多改进,以提高编码效率:(具体看书)
- H.261 只支持两种图像格式,而 H.263 支持 5 种图像格式:
- 图像分块方式改进
- 运动补偿方式的改进
- 量化处理的改进
- 编码方式的改进
- 运动估值像素精度的改进:半个像素精度的运动估值
- 不受限的运动向量
- 先进预测模式
- PB 帧格式的使用
- 使用基于语法的算术编码
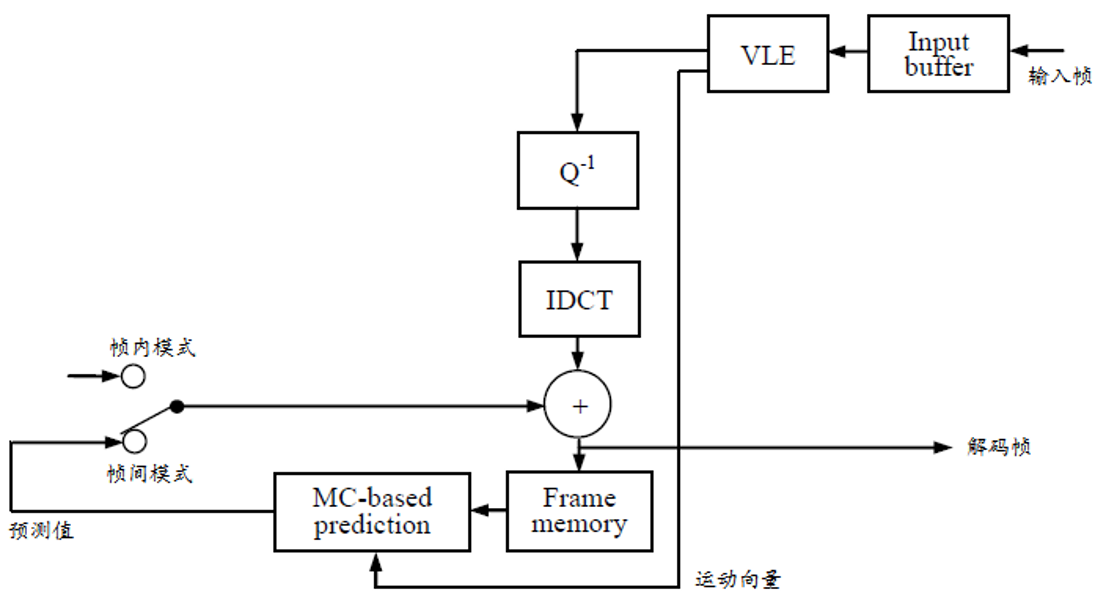
H.263 H.264 编码器:引入了帧内预测
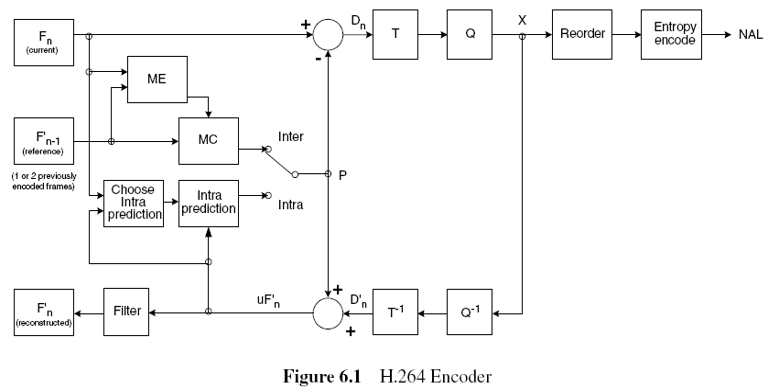
H.264
网络多媒体基础
网络多媒体的概念
- 计算机网络
- 概念:计算机网络是以信息传输、资源共享为目标,通过通信线路连接起来的自治计算机系统的集合。
- 分类:
- 视角一(网络覆盖范围):以网络大小为标准,即根据网络的覆盖范围与规模来进行分类,将计算机网络分为个域网 、局域网、城域网和广域网 4 种类型。
- 视角二(传输技术): 按照网络使用的传输技术来分,可以把计算机网络分为广播类型的网络和点到点类型的网络。
- 构成:计算机网络是一种信息基础设施,它的技术焦点是网络体系结构,包括协议分层模型、协议的数据报文格式、网络节点地址与名称管理、路由算法、数据传输及其管理等。
- 体系结构(computer network architecture):指网络的技术构成方式,核心内容是网络协议及其分层模型。
- 分布式系统
- 概念:分布式系统是指以计算机网络为基础,由部署在连网的计算机上的程序或组件,通过传递消息进行通信并协同工作的软件系统。这个定义涵盖了所有可有效部署在连网计算机上的软件系统。
- 计算机网络与分布式系统
- 区分:计算机网络和分布式系统是两个容易混淆的概念。我们已经阐明,计算机网络是一种信息基础设施,它的焦点是网络体系结构。而分布式系统则关注组件的协同工作和应用。
- 网络多媒体
- 概念:泛指一切与多媒体相关的网络技术。例如,多媒体传输协议、流媒体技术等等。
- 分布式多媒体系统
- 概念:是指以传输和应用多媒体信息为目标的分布式系统,典型代表。视频会议、互联网电话、交互式电视、远程教育、远程医疗、网络视频监控、网络游戏等
- 特点:
- 1. 多媒体应用程序通常是高度分布的:并且在通用的分布式计算环境中使用。与其他分布式应用程序竞争网络带宽和计算资源。
- 2. 多媒体应用程序对资源的需求是动态的:分布式多媒体应用可能还涉及其他间歇性负载,需要赋予系统高可用性和良好的可伸缩性。
- 3. 多媒体数据是连续的和基于时间的:所谓连续的和基于时间的特性,是指多媒体 数据内部的一种前后关联性,其比特或数据块之间服从严格的先后顺序。流用于描述这种时序关系的既形象又确定的一个概念。所谓数据流就是基于时序的连续数据。媒体应用程序在处理这种连续数据的时候需要特别注意保持数据的时序关系。
- 挑战:
- 异构网络与随机性:建立在异构物理网络和 IP 协议基础上的互联网,是一个不保证服务质量的基础结构,它的传输延时、带宽和丢包率具有随机性。
- 服务质量 QoS:带宽(bandwidth)、延时(delay)和丢包率(lost rate)3 个主要参数
多媒体的传输
研究方向
- 第一个研究方向:针对网络的异构性和不确定性,着眼多媒体数据本身的特点,在信源端采用分层的可伸缩性编码,通过多种速率来传输不同质量的多媒体数据,从而适应传输链路、交换节点和接受终端的异构性。
- 第二个研究方向:是从网络技术本身着手,对现有网络模型和基础结构进行改进,例如,提高网络传输带宽、增强路由器等交换设备的能力、提供资源预留与组播服务等。
- 第三个研究方向:是分布式多媒体系统本身的体系结构,例如基于中心服务器的体系结构有助于简化数据管理,但存在较高的延时,而对等模型(即 p2p 网络模型)则有助于提高系统的可伸缩性,但管理复杂。
组播技术
网络传播方式:网络有 3 种传输方式:这就是广播(broadcast)、单播(unicast)和多播(组播,multicast)
- 广播:广播意味着源端向子网的每一个主机都传送同样的数据包,无论这些主机是否乐意接收这些数据包。
- 单播:单播是指在发送者和接收者之间实现的点对点传输. 如果发送者同时给多个接收者传输相同的数据,它必须通过多个连接来发送复制的数据包
- 组播:后面详细阐述组播
- 组播概念:
- 组播是指将源端的数据传送给一组特定接收者的传输方式。
- 网络组播:是指通过网络交换设备(路由器)建立一种树状分发结构所实现的组传输。组播大大减轻了源主机的负担,因为源端只需要发送一个数据流;也能够显著降低网络通信量。
- 应用:广泛应用于一对多(one-to-many)的传输
- 新闻/体育/股票/天气信息的更新发布
- 远程教育(Distance Learning)
- 网络路由信息更新(routing updates)
- 远程会议(Teleconferencing)
- 分布式交互式游戏和仿真
- 内容发布(Content distribution)
- Web 缓存更新(Web-cache updates)
- 数据库应用(Database replication)
IP 组播构成
- IP 组播是网络组播的一种具体实现,它通过 IP 路由器构造互联网中的组播分发树,使用 IP 组地址标识群组,通过 IGMP(Internet Group Management Protocol)协议管理群组关系,并包含若干 IP 组播路由协议。
- IP 组播涵盖三个方面的内容:用户(服务模型)、群组关系管理协议、组播路由协议
用户模型
使用 IP 组地址标识群组。如 D 类地址
- 范围:224.0.0.0 – 239.255.255.255
- 组地址的分配问题
- IANA 指定了一些永久地址 (Well-known : 224.0.0.x and 224.0.1.x );其他组地址是临时组地址(Transient addresses),需要动态分配
- 每个组地址代表一个主机群组(host group)
- IP 组地址是非结构化的(flat address space)
- 源端无需管理目标主机的 IP 地址
- 群组成员主机可以位于互联网的任何地方
- 群组规模(group size)是任意的
- 成员主机可以任意加入或退出群组
任何子网中不能出现同一数据的副本(???TODO)
群组关系管理协议
- 主机通过 IGMP 协议告诉指定路由器希望加入并接收某个特定群组的播组信息,同时路由器通过协议周期性地查询子网内某个已知群组的成员是否处于活动状态,即对该网段是否仍然存在属于某个群组的成员主机保持更新(update)。
- 作用:在子网中建立、维护和撤销群组的信号协议“signaling protocol”。
- 目标:保持路由器对整个局域网上群组关系的更新(keep router up-to-date with group membership of entire LAN)
- 路由器不需要知道所有成员的存在,而只需要知道是否有成员主机存在。
- 一个网络选择一个路由器充当查询者(querier),又称指定路由器
- 查询者周期性发送群组关系查询报文(IGMP Membership Query message)到一个特定地址(all-systems group ,224.0.0.1)
- 所有主机接收到该报文后,启动一个随机计时器(random timers,0~10 秒)
- 一旦有一个主机超时,它就发送一个群组关系应答报文(Membership Report)到组 G
- 其他主机也接收到该报文,立即终止其定时器
- 路由器负责监听所有群组的应答报文,如果一个群组未给出应答(超时),路由器就终止对该群组报文的转发
组播路由协议
- 组播路由协议的作用:在网络层建立组播分发树,实现组播数据报文的传输
- 域内组播路由协议和域间路由协议。域内路由协议又分为密集模式和稀疏模式两种。密集模式组播路由协议一般采用泛洪技术实现。稀疏模式采用最短路径和共享树技术实现。典型:DVMRP 和 MOSPF。
- 组播路由的基本目标:在网络层为传送组播数据包而建立组播分配树
- 组播树的叶结点是指包含有群组成员主机的子网 (detected by IGMP)
- 组播路由是一个比较困难的课题(Multicast service model makes it hard)
- 匿名性和动态性(dynamic join/leave)
- 基于泛播与剪枝技术的路由协议
- 首先在整个网络泛播组播数据包,然后剪除不含成员主机的网络分枝,属于这类技术的协议: 距离向量多播路由协议 DVMRP, PIM-DM。
- 基于链路状态的路由协议
- 一个路由器知道有成员主机加入群组时,它就在整个网络广播该群组关系;一个路由器接收到组播数据时,它就利用 Dijkstra 算法计算到目标主机的最短路经,并转发组播数据。多播开放最短路径优先协议 MOSPF。
- 具体:DVMRP 协议
- 是一种互联网多播路由协议,为互联网络的主机组提供了一种面向无连接信息多播的有效机制。
- 是一个“内部网关协议”,适合在自治系统内使用,不适合在不同的自治系统之间使用。
- 当前开发的 DVMRP 不能用于为非多播数据报路由,
- DVMRP 数据包封装于 IP 数据报中,使用的 IP 协议号为 2,这点与 Internet 组管理协议(IGMP)相同。
- DVMRP 整合了 RIP 协议中的许多特性,核心算法是截断反向路径转发(Truncated Reverse Path Forwarding,TRPF)技术。
- 具体:DVMR 协议的缺陷
- 像其他基于距离向量的协议一样, 受无穷计数(count-to-infinity)和环路影响(transient looping)
- 伸缩性受到类 RIP 协议的制约,也引入了新的伸缩性问题(scaling limitations):路由器的(S,G) 状态,使路由器存储开销比较大!
- 广播对网络冲击比较大
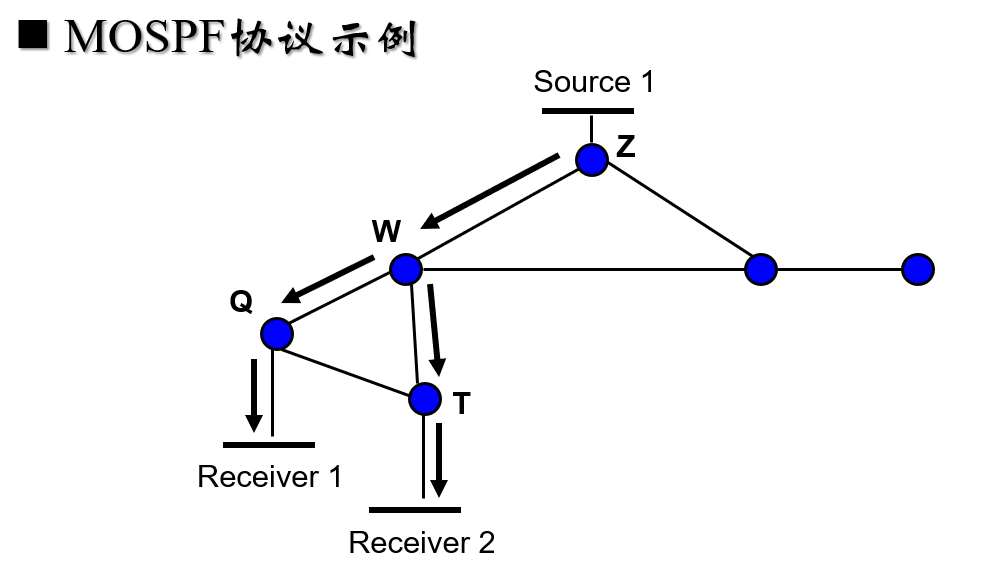
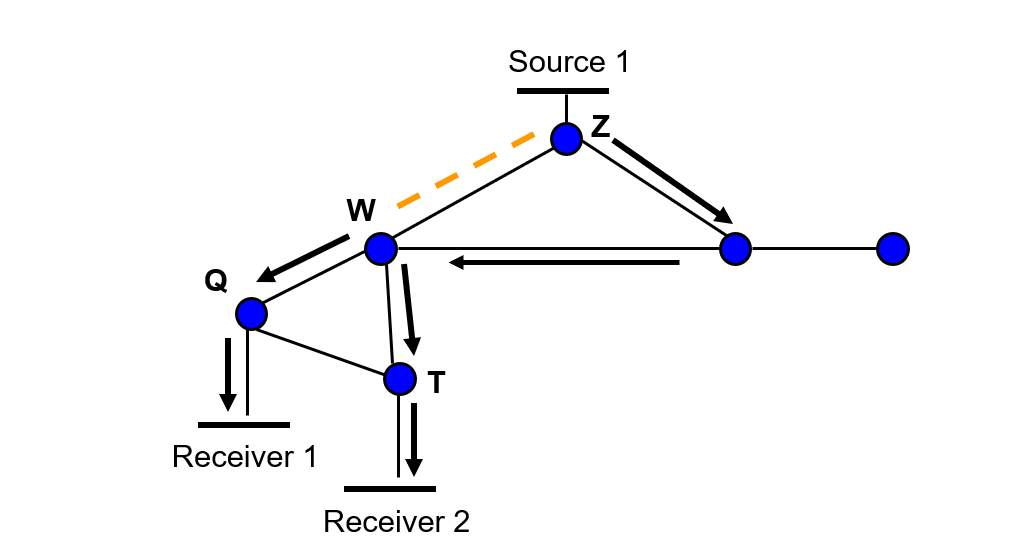
多媒体传输协议
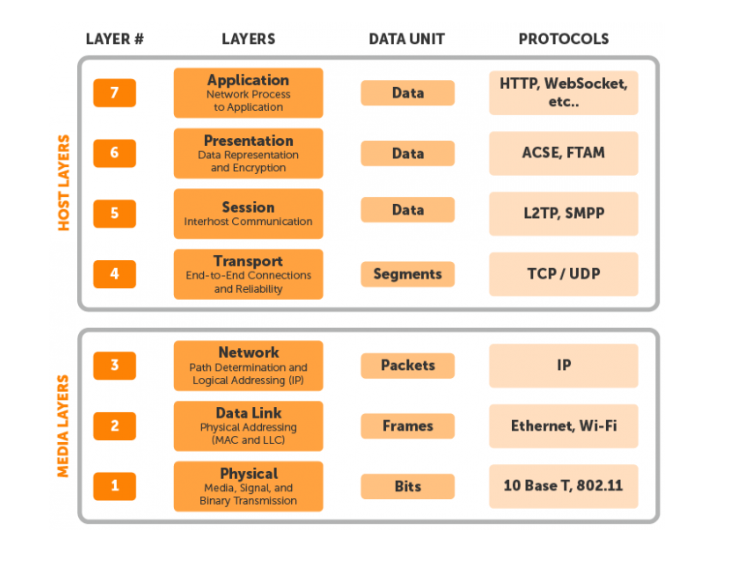
- 多媒体传输协议的整体层次结构
- 应用层:RTMP、RTSP(应用层到传输层还有 RTCP 和 RTP?)
- 传输层:TCP、UDP
- 网络层:IGMP、...
- RTP 协议
- RTP(Real-time Transport Protocol,实时传输协议)协议是一种为在互联网上以单播或多播方式传输实时多媒体数据而开发的协议,该协议的主要目标是解决多媒体数据流的同步问题
- 混合器工作原理
- 端系统:产生或接收源数据的主机系统(如果是产生源数据,该端系统即为同步源,例如连接摄像机的计算机等)
- 混合器:生成 RTP 保温的主机系统(混合器可以实另一个混合器的同步源,也即构成混合器->混合器的形式)
- 转换器:和混合器都是 RTP 级的中继系统。转换器用在通过 IP 多播不能直接到达的用户区。
- 应用:
- 从应用开发的角度看,RTP 协议是应用程序的一部分。通常由应用程序将多媒体数据封装到 RTP 数据包中,然后交由套接字(Socket)将 RTP 数据包封装到 UDP 数据包中,进而封装到 IP 包中。
- RTCP 协议
- 来源:RTP 协议用于封装媒体数据并提供时序信息。但是 RTP 协议本身并不保证多媒体传输服务质量,也不提供流量控制、拥塞控制服务。So,进一步提出了 RTCP 协议。
- RTCP(Real Time Control Protocol,实时控制协议)协议配合 RTP 协议使用,其主要任务是为通信双方的应用程序提供统计信息,这些信息包括实时数据包的数量、传输过程中丢失的数据包数量、往返延时、延时抖动等。
RTSP 协议
- RTSP 协议处于 RTP 协议和 RTCP 协议的上层
- RTSP 可以对流媒体提供诸如播放、暂停、快进等操作
- RTSP 协议会话过程
- 客户机首先通过 HTTP 协议从 Web 服务器获取所请求视频服务的呈现描述文件
- 然后客户机根据上述信息向视频服务器请求视频服务。
- 初始化完毕,视频服务器为该客户建立一个新的视频服务流,客户端与服务器运行实时流控制协议 RTSP
- 当服务完毕,客户端提出拆线(TEARDOWN)请求
- 目前流行的流媒体协议

流媒体技术
目前较流行的流媒体技术栈
- 视频以 H.264 编码,以 FLV 格式封装,以 RTMP 协议传输
- 代表为:B 站直播,youtube/twitch
调研问题
- 为什么目前 RTMP 比 RTSP 在流媒体直播应用中更流行?
- 为什么 B 站的视频流是 FLV 格式而非 MP4 格式?Flash 不是要被淘汰了吗?
flv.js 作者的回答
作者:谦谦 链接:https://www.zhihu.com/question/51997376/answer/129065505 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
flv.js 做了三件事:
- HTML5 原生仅支持播放 mp4/webm 格式,flv.js 实现了在 HTML5 上播放 FLV 格式视频
- 使 Bilibili 网页端平滑过度到 HTML5 播放器,历史遗留不再是障碍
- 对于视频直播,在 HTML5 上支持了延迟极低 HTTP FLV 播放,解开网页端直播对 Flash 的依赖一些人问我为什么不直接采用 MP4 格式,并表示对 FLV 格式的厌恶这个问题一方面是历史遗留问题,由于视频网站前期完全依赖 Flash 播放而选择 FLV 格式;
另一方面,如果仔细研究过 FLV/MP4 封装格式,你会发现 FLV 格式非常简洁,而 MP4 内部 box 种类繁杂,结构复杂固实而又有太多冗余数据。FLV 天生具备流式特征适合网络流传输,而 MP4 这种使用最广泛的存储格式,设计却并不一定优雅。
这里我不想谈论多媒体封装格式的优劣。flv.js 是在 HTML5 上实现自定义视频格式播放的一个较好的范例,充分利用了 Media Source Extensions, Fetch API 以及 ECMAScript 6 等 HTML5/Web 上较新的技术,并考验着这些 API:开发期间发现 Edge 对 Fetch API 的支持存在 bug,发现各个浏览器在 MSE 的实现细节上都有一些差异和问题,发现 Safari 的 MSE 实现健壮度较差(滑稽)。
在 flv.js 项目初期,Media Source Extensions (MSE) 在国内处于无人问津的状态;而 MSE API 已经过近 4 年的发展演进,是 HTML5 多媒体相关最重要的 API 之一。MSE 是 HTML5 上实现自定义格式播放的关键,flv.js 开源也是希望 MSE 能被更广泛地了解和应用。
最后,Chrome 等浏览器正在加速 Flash 淘汰的进程,HTML5 video 由各浏览器厂商实现了高性能硬解,MSE 作为媒体格式扩展的补充,flv.js 证明了当前 HTML5 多媒体技术已超越陈旧的 Flash。
该页面下另一个人的回答
作者:飞翔的蜗牛 链接:https://www.zhihu.com/question/51997376/answer/134109395 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
...而所有直播协议延迟和实时性最好的就是 RTMP,在中国看美国的视频直播延迟也能控制在 1 秒内,很神奇的一个协议。但是 RTMP 有个缺点,他只能在 PC 端上用 flash 来直播,不支持移动端。如果要在手机上网页端用 html5 播放,那么只能选择 HLS,而且 HLS 在中国看美国的视频直播有时候高达 18 秒的延迟。 而真正能解决这个需求的,目前来说只有 flv.js,通过 HTTP-FLV,在手机网页端用 html5 播放,延迟是能控制在 1 秒内的。 其实很多外国游戏直播网站都是用 RTMP 来直播。他们都是在手机上用 APP,用 C++来解析的。看过一个英文论坛上的讨论,他们的技术对于网页端播放低延迟直播几乎无解,网页端非常难。很多人都没有意识到,这是非常有技术含量,非常伟大的一项技术。 至于很多人为什么不用 MP4,而表示对 FLV 的厌恶的问题。做为一个技术控,我是能理解 B 站为什么用 FLV。因为 adobe 的 RTMP 和 FLV 的格式,都设计的非常的简洁和漂亮,所以才有如此神奇的性能。而对于开发者也是一种解脱,无论用 C 或者 js 处理,代码也都非常简洁。如果你让他用 js 去写 MP4 那一坨坨代码,就陷入无穷的技术坑。所以做为一个技术控,用 FLV 是再自然不过的事情。用 FLV,性能好速度快用户爽,代码易读易控开发者爽。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!