CCFADL105——大数据系统实践:从MapReduce到融合计算
大数据系统实践:从 MapReduce 到融合计算
主讲人:郭振宇(蚂蚁金服分布式计算总监)

融合计算模型
观察/趋势
举一个蚂蚁金融一个常见的应用场景:扫码支付
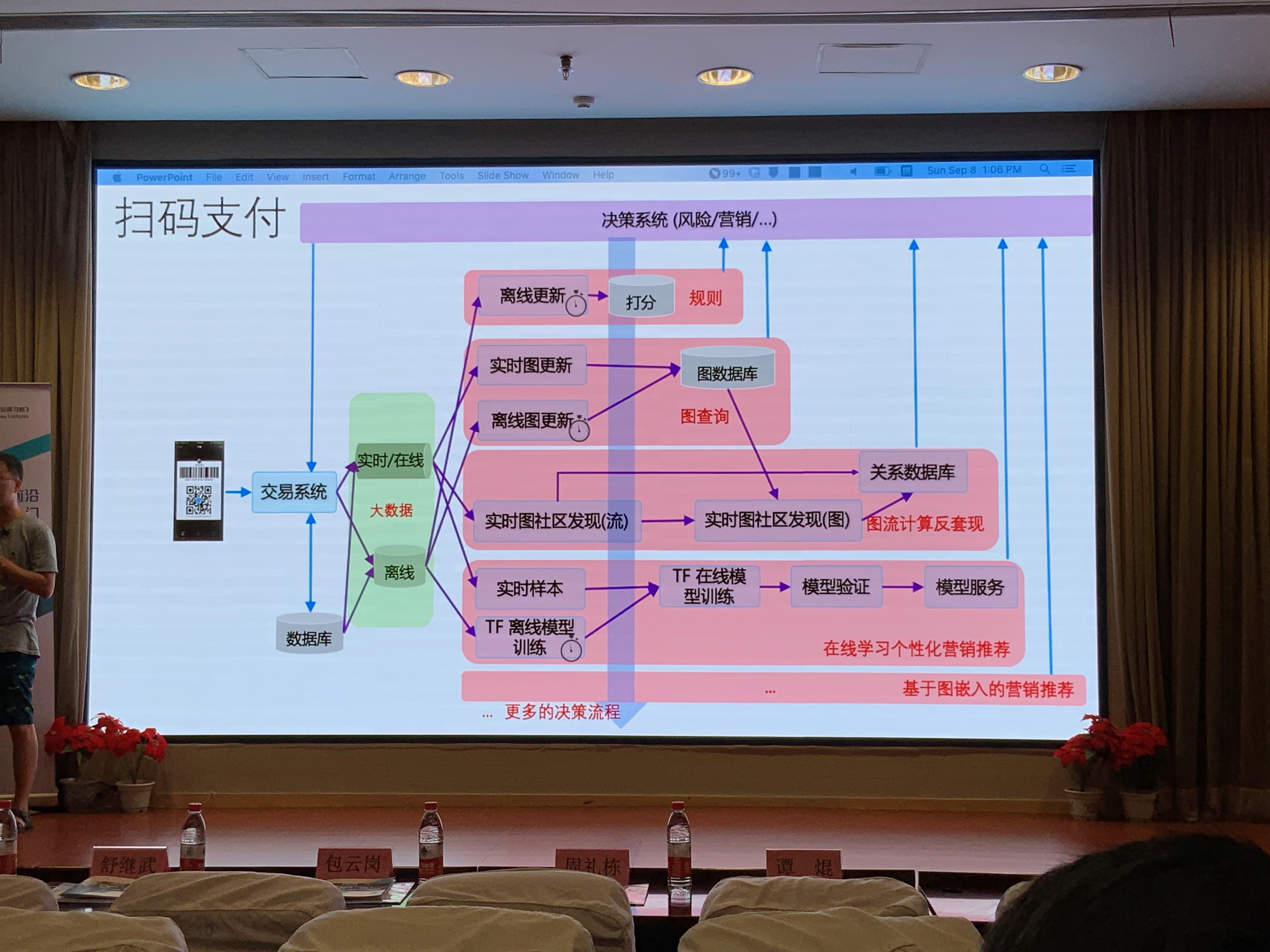
审视机器学习(或者大数据分析)产品三个层面的发展:
- 计算范畴:统计->规则(专家会议沉淀)->图->AI->复杂决策
- 计算复杂度:静态线性工作流->静态图工作流->动态工作流->多流->多流融合
- 质量:时效、安全/隐私、数据可靠性。
实际上真正的 Machine Learning Code 只是很小的一部分,图源:《Hidden Technology Google》
而应用要落地,关键的问题在:
学习/开发/调试的成本
- 对接很多独立的引擎/框架
- Ad-hoc/碎片化的集成/联调(多机联调)
运行时质量
- 破碎的上下游衔接
- 形象点说,就是:上面跑数据不确定,下面就可能接受到不对的结果,
- 具体在:接口/时效性/一致性/故障恢复/中间状态管理
- 对于中间状态管理的解释:生产者(上游)通过 HDFS 存放中间状态(产品),消费者(下游)不知道什么时候可以删除而不产生危害,导致存储过载、溢出。
- 盲目调度,存在很多优化的空间
- 资源/数据/计算/服务
- 冗余/低效的数据传输/拷贝/计算等
- 安全隐私
- ...
- 破碎的上下游衔接
- 运维效率
- 多引擎/平台异构运维
胶水
平台化,将不同工作胶合在一起,常通过 GUIWorkFlow 的形式展示出来,一些公司已经有一些相关的工作。
e.g. Azure ML Workflow, Google Kubeflow
优点
- 包容性好
- 易用
- 局限性
- 组件质量/接口参差不齐->接口难做
- 组件对于胶水来说是黑盒->跨接口优化难做
想法:胶水->统一的分布式支撑
目标

融合计算:本地编程、自动云化、渐进融合
核心挑战 1:统一的通用编程抽象/执行模型是什么
前面的讲座中已经多次提到了抽象的重要性,抽象就意味着:
- 抽取面对不同分布式计算模式下的共同需求
- 甚至混合模式下的需求。
核心挑战 2:如何解决通用和特定之间的固有矛盾
通用性和领域专用性常看做是不可调和的矛盾。
- 一般情况下,越通用,解决特定场景能力越弱。
- 抽象是一种通用性的体现,而不同计算模式的不同需求/特定优化则体现了领域专用性
融合计算编程抽象
为何需要分布式计算?以 MapReduce 中使用的字符计数问题为例:
- 对于单机:存储空间不够、计算能力不构、
- 分布式计算目标:提供远超的单机的存储、计算能力,包装成单机的假象使上层没有意识到改变

状态切分
MapReduce 的启发,状态切分成 slice,两个子方案,一是不需要代码改动的方案:remote memory,file system。二是需要代码改动的:KV,database
避免数据共享冲突的方法?调整架构
| 控制流架构(冯·诺依曼) | 数据流架构 |
|---|---|
| 执行由控制流驱动 | 执行由数据流驱动 |
| 控制流导致状态访问冲突 | 数据是无消息/无冲突问题 |
改写代码是必要的。
回到 MapReduce
MapReduce 做的事情是将整个字符统计拆分成两个任务,Map 任务,Reduce 任务。
实际上各种计算范畴(computation paradigm)表达能力都可以通过数据流二部图(Task Object)表达出来,复现 PPT 展示的表格:
| 范畴(Computation paradigm) | Task | Object |
|---|---|---|
| CPU Computation | instruction instance | register/memory operand |
| MapReduce | mapper, reducer instance | input & output (memory/HDFS) shards/buckets |
| Graph Traversal | graph shard worker traverse instance | graph shard state snapshot, input/output messages |
| Streaming | streaming operator execution instance | messages transmitted in channels among operators |
| Tensor Computation | tenser computation operator instance | tensors |
| Parameter sever based model training | worker running for one iteration | data,model parameters |
| Actor based computation(object oriented computation) | actor method execution instance | actor method input/output, actor state snapshot |
但是,Master 是个 exception,Master 是有状态的,相对于 Master 和 Reduce,对于有状态的 Master,MapReduce 论文中巧妙的忽略了这一点,对于单点故障,只需重启整个任务即可,数据流框架中不可采取这种“莽撞”的方法。
无状态任务 vs 有状态任务
- 无状态
- 大多数数据流计算(MapReduce,Dryad,Spark)
- 大多数 SOA 里面的 Method Call
- 随便哪里都能跑
- 有状态
- 某些有迭代的数据流计算(Tensorflow,Grap Computation2)
- 存储操作
- 带状态的服务操作(大多数 Job Master)
- 执行逻辑必须和状态绑在一起
编程抽象之 服务
服务 vs Actor
- 服务 = [同构 Actor]*(一组同构 Actor 的集合),Actor 是单进程的。蚂蚁金服团队认为多线程一些地方还存在相似性和优化空间,更适合作为抽象单元,所以最终选择以服务作为自己的抽象单元。
- 尽量隐藏分布式计算带来的复杂度
- Scale out
- Elasticity 弹性,日夜差别
- Load balance
- Fail over
小结

静态数据流 vs 动态数据流
业务的需求,动态越来越多,NLP/Reinforcement learning,Nested Graph。没办法一下子把图给全。

数据流图是一边跑一边长出来的。
核心编程抽象
本地化编程->分布式编程
三元一一对应
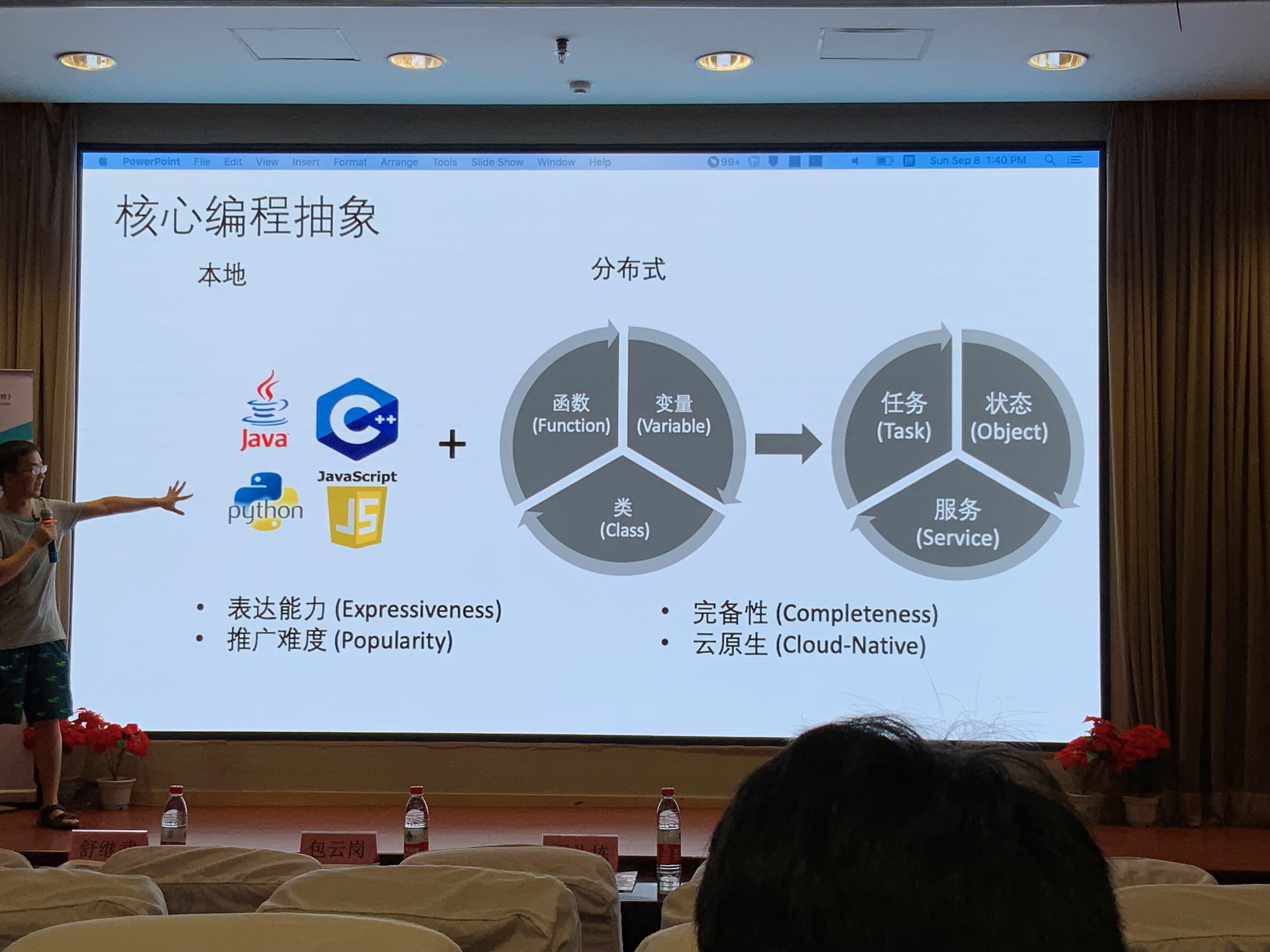
eg

本地编程(On-Premise Programming)
微内核架构
- 不仅仅是性能问题
- 多方面统一和特定之间的两难问题
- 最重要,执行统一的架构和合约,避免无序
- 团队合作
- 简化产品化/研发效能的问题(e.g.通过 AOP)
插件分类和实现
eg:执行流调度、状态管理、服务部署策略、资源分配策略、进程故障恢复、状态故障恢复
优点:
- 模块可重用,不同场景需求选用不同组合
- 根据场景制作特定优化插件
- 功能级别相同插件可替换、方便排查问题
- (基本)独立开发,无缝集成,方便团队合作
缺点:
- 模块繁杂,系统配置复杂(状态管理插件存放的位置,HBase,Redis,放哪里都有区别)
- 插件抽象要求高,还完全 stable
- 某些插件相互依赖、不独立(理论上是笛卡尔乘积组合情况,但耦合性降低现在仍然是努力的目标)
融合优化
Level of indirection solves everything
可以解决谁产生谁消费的问题,但是交互比较麻烦。
Problem: The indirection layer does enable flexibility but also brings cost
从静态数据流(static data flow)思考,并不会出现这种问题,图确定,必然有。
Back to the future,借鉴过去经验,想着能不能把动态往静态拉一把,我们还需要获取一些信息。
基于为微核架构的 Runtime optimization hybrid run-time
Our Work
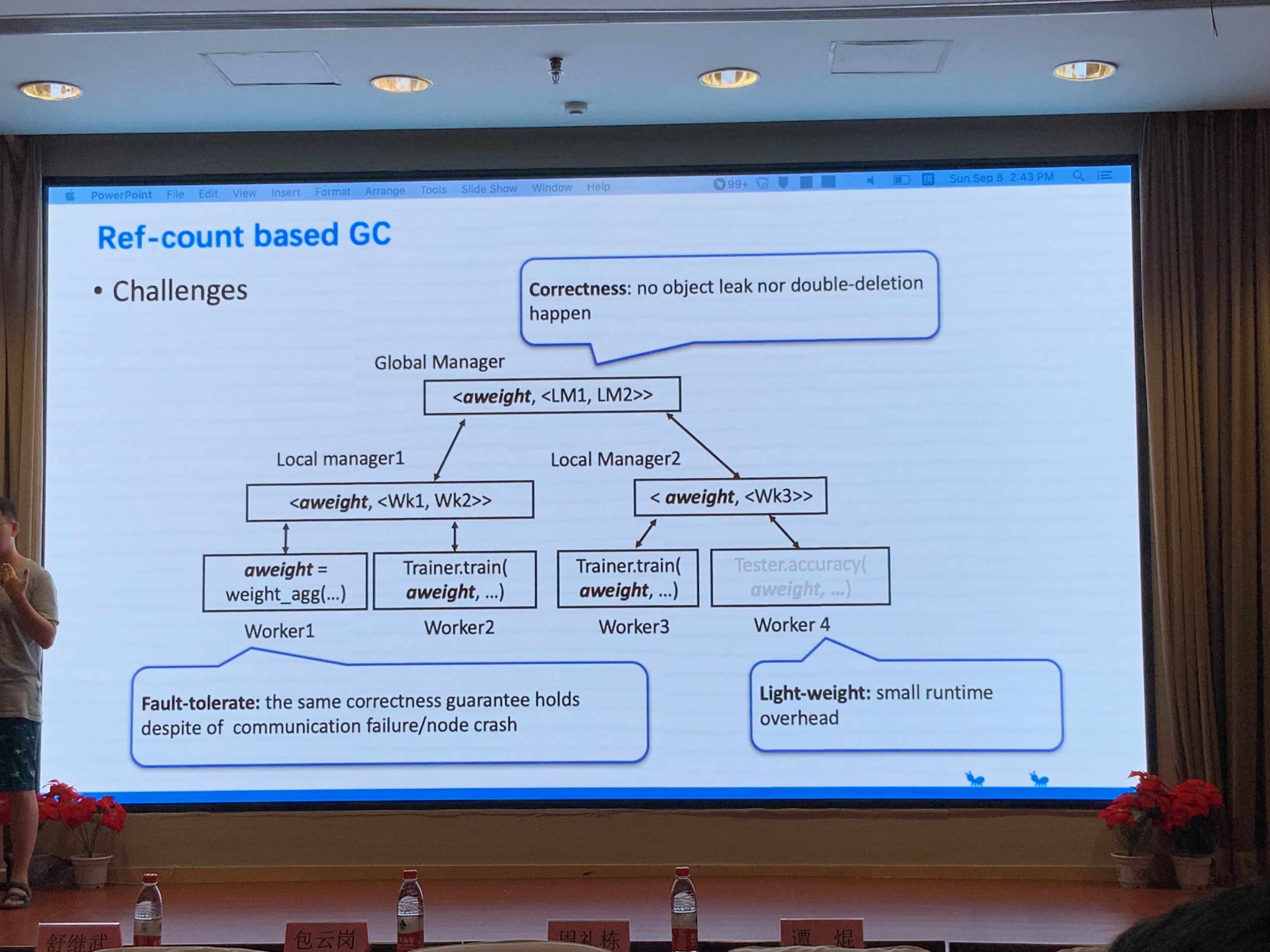
Distributed Gabbage Collection
现在解决方案存在的问题:LRU(页面置换算法:最近最久未使用),删 object,但是可能还会用,删了可能会触发后面请求的 Failue,导致:
- 负担增大
- 无法找回
蚂蚁金服的解决方案:
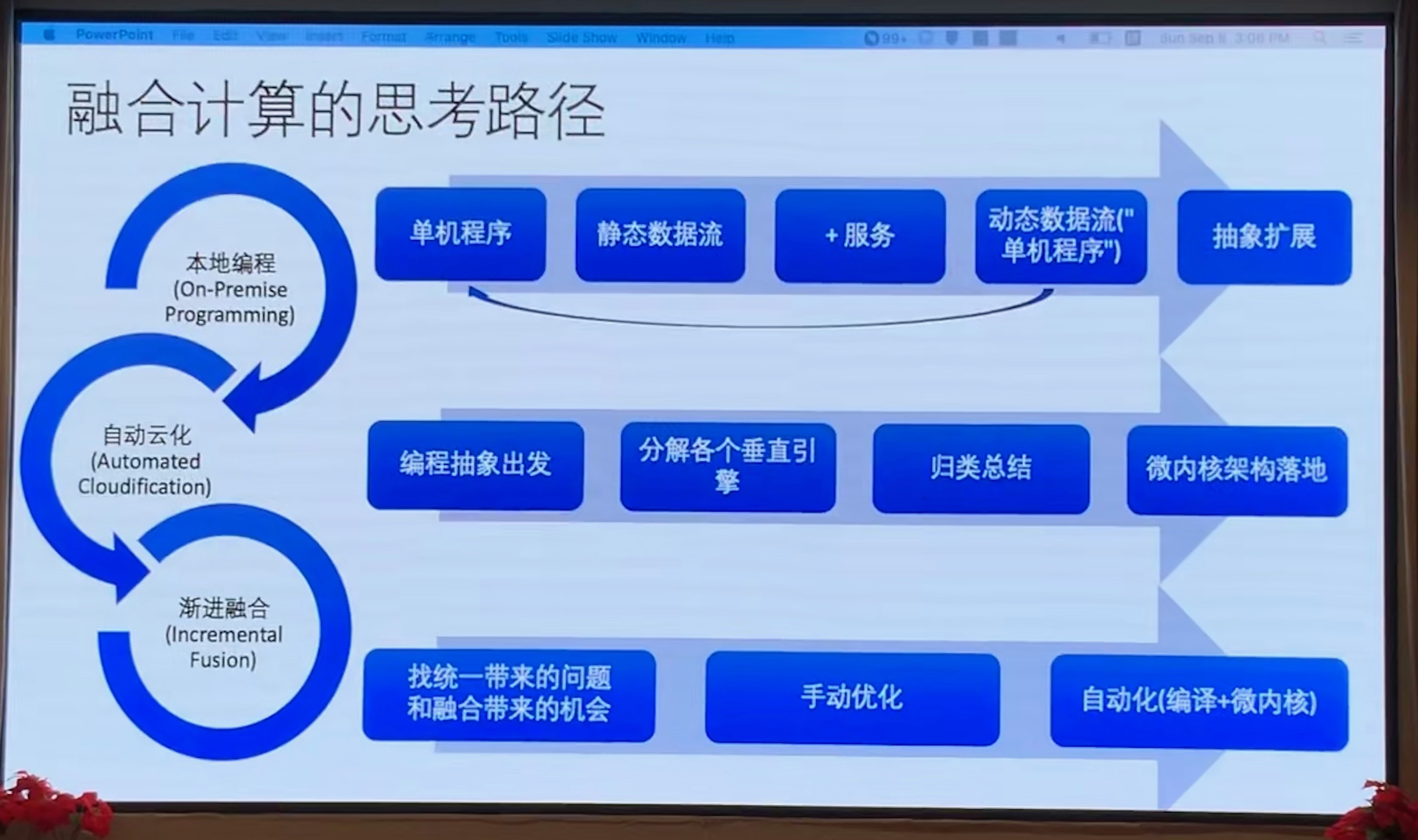
融合计算的思考路径
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!