CCFADL105——大数据系统的演化:理论、实践和愿望
大数据系统的演化:理论、实践和展望
主讲人:周礼栋老师(微软亚洲研究院副院长,MSRA 被称为系统方向的黄埔军校,肇国老师评价其为非常 Perspective 的一位老师)
前言
作为第一个 Talker,先做一个比较宏观的演讲,整个分为两部分。 除了必要的知识点以外,我们更需要以系统的视角,关注方法学(重新思考)。
回顾大数据系统的发展历程:Big Data Systems
强调了抽象的重要性,一个好的抽象,可以将要进行的任务很好的表达出来,同时还要具备高效性,可以被高效的实现。
2010 年以前的工作:Foudation
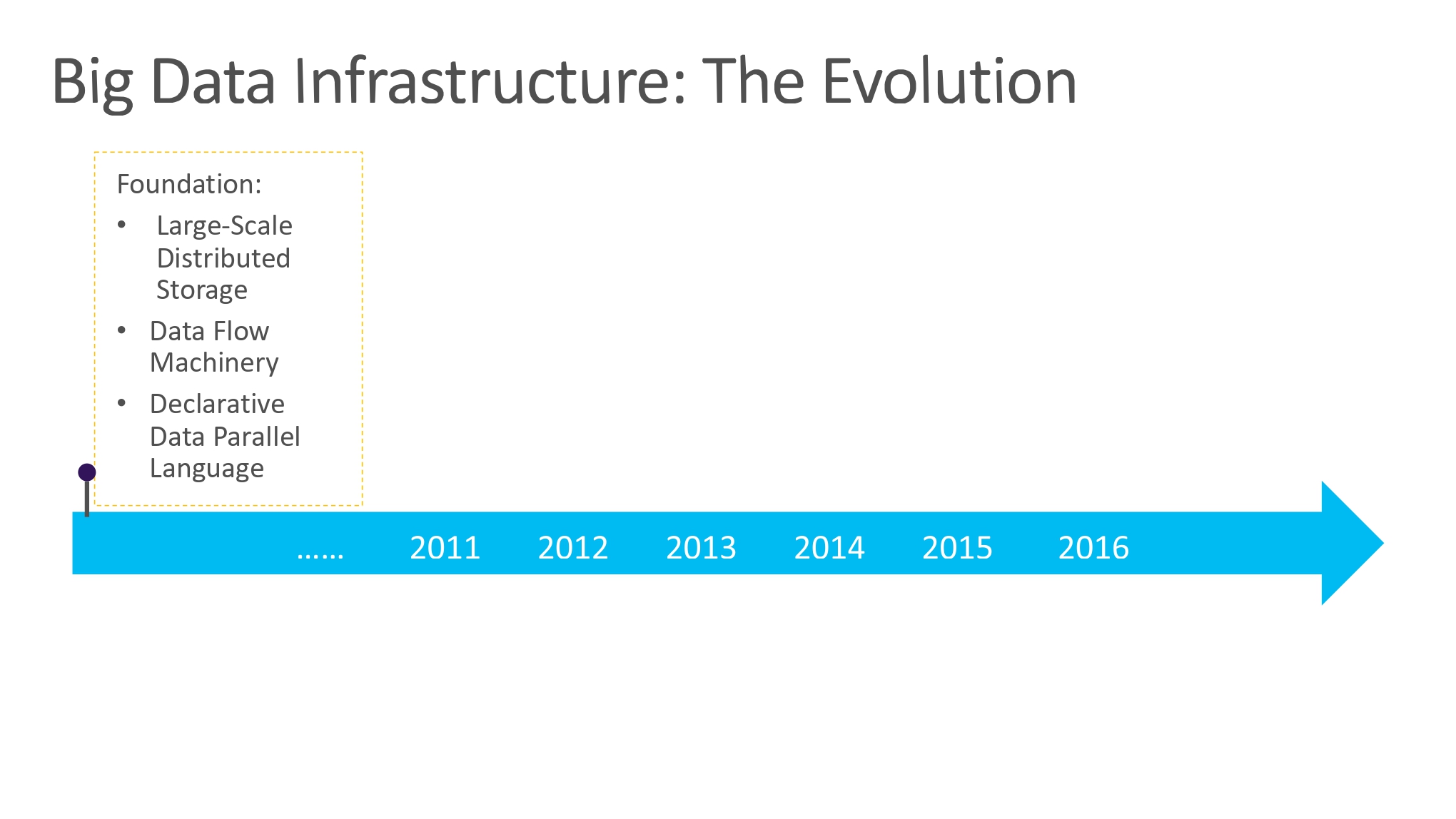
对于 MapReduce 的横空出现,学界对于 MapReduce 存在一些争论,一些数据库的巨擘认为 MapReduce 是对数据库已经建立起来的一些规则也好,基石工作也好的破坏,技术上是一种倒退,而微软则在 Google MapReduce 的基础上尝试填补上述争论,微软认为数据库和 MapReduce 是存在结合点的,可以向上提供原有的 SQL relation algebra
- 谷歌: MapReduce -> 并行/分布式/优化 -> 高效执行
- 微软:数据流 -> 原有数据库接口 -> MapReduce -> 并行/分布式/优化 -> 高效执行
2011-2012 的工作:Holisitic Code Optimization
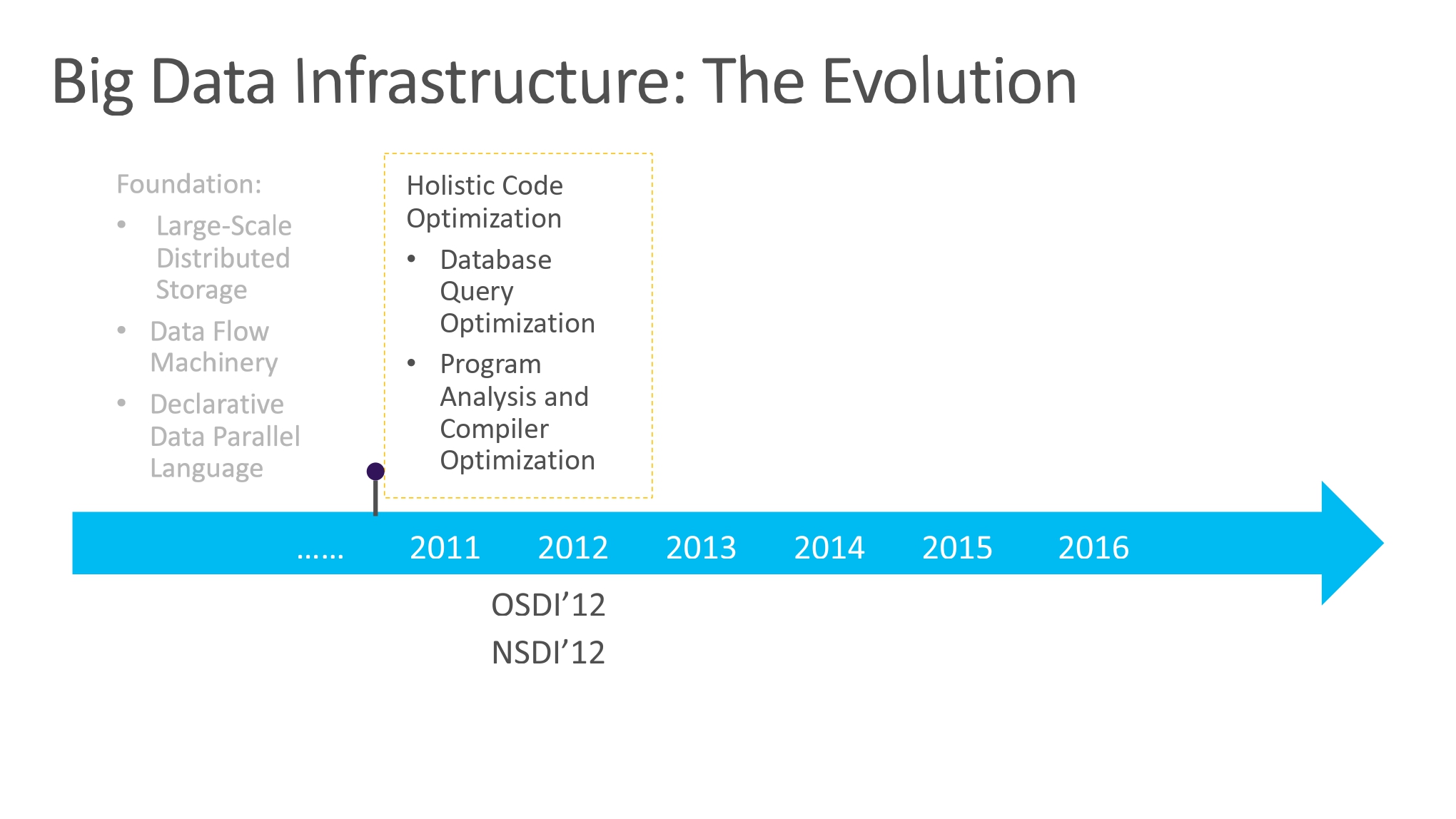
数据库里面的优化和编译器的优化可以结合起来,思路:最优执行,优化执行。(当然整体还是建立在数据库的思维上)
PeriSCOPE 项目,出发点希望将 SQL-like code 进行编译优化。
- 代码段是在多机器并发执行
- 纯编译优化只是很小的局部
SQL 生命力旺盛的一个原因是其隐藏了很多优化的细节。将 SQLize 的特性深入到全局概念,全局优化。
全局优化关键是优化目标、关注点的改变:数据传输(Data Shuffling)消耗:
- Column Reduction:延迟产生列
- Early Filtering 提前合并减少列
- Smart Cut
Research to Production
从研究所的科研突破到是计划产品部署过程中还会存在着一些问题,不管是科研人员和业务部门人员思维上差异也好,工作环境也好,所以在转化过程中我们还需要做到以下几点:
- 新颖与保守兼顾(考虑到业务部门的保守性)
- 需要适应真正的工作(而非 Benchmark 或者模拟数据)
- 无错、无不良影响、无不可预测行为(相较于成熟的旧技术,新技术如果以出错为代价,性能提升再多都是徒劳)
- 必须是收敛且低开销的(泛用性强,经得起工作集的改变)
- 后期维护的代价要小、复杂性低(方便迭代)
2013-2014 的工作:Scheduling and Resource
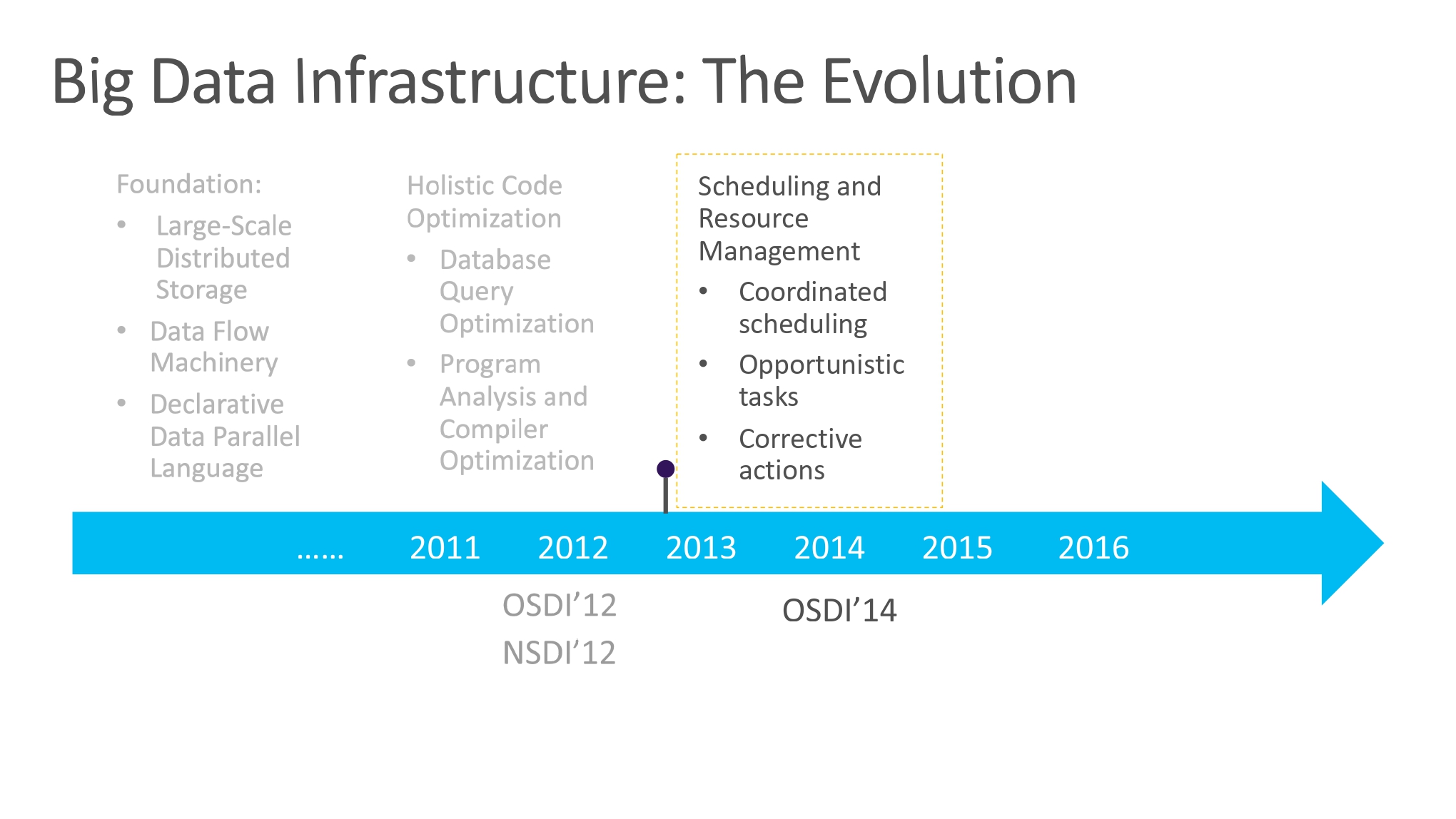
从单一 Job 的优化到多 Jobs 的优化,引入调度优化的角度。
大规模集群的多任务调度优化已经不仅仅是一个算法上的问题,因为集群中机器状态未知是常态,而且各自完成任务的预期也是 Unpredictable 的。
2015-2016 的工作:Beyond Batch Processing
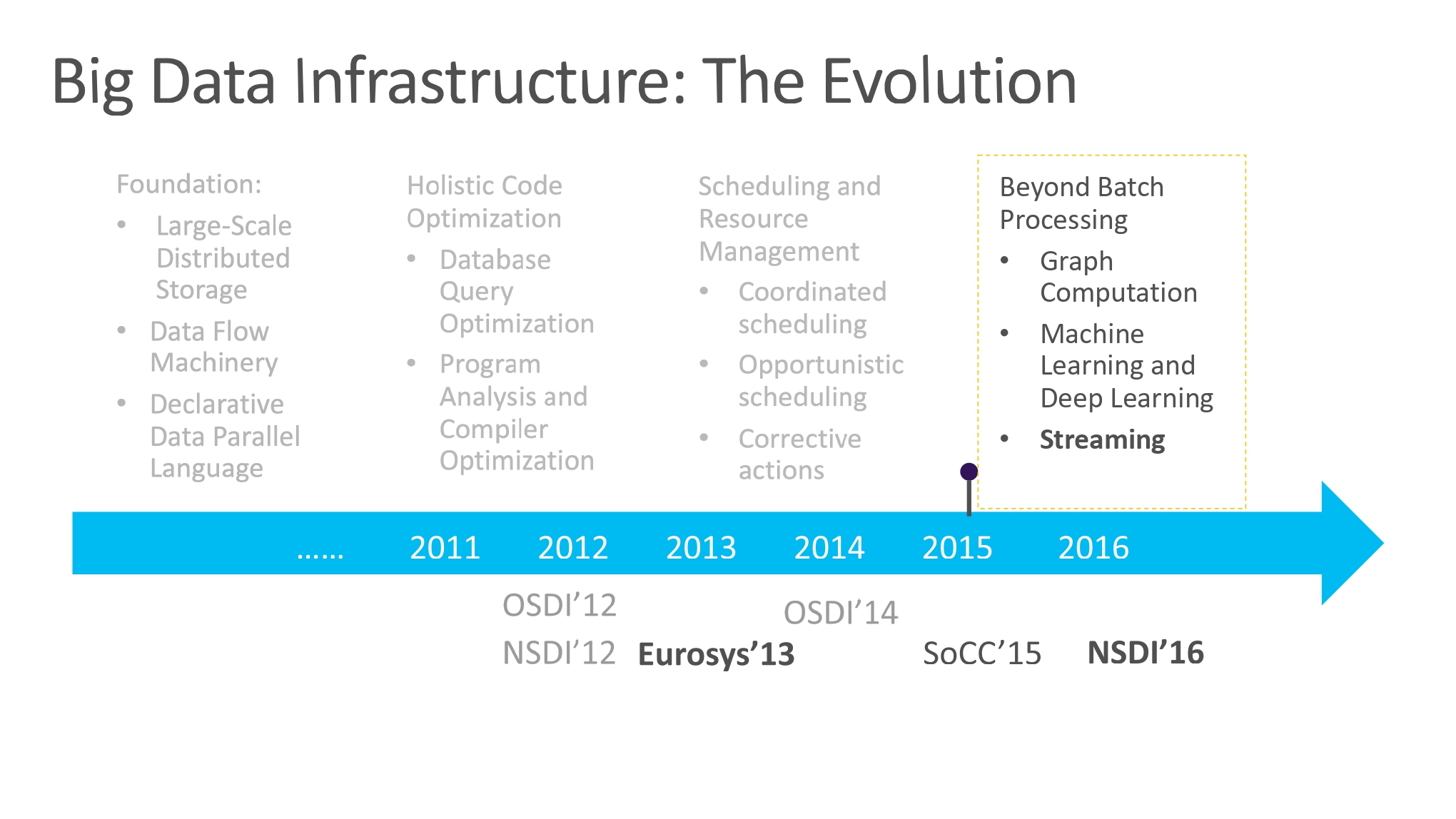
重新审视思考方式:图计算、机器学习、流等概念的推广。从先前的 Scope 发展衍生出 StreamScope:分布式大数据可靠流系统。
微软内部商用大规模流系统
- 从批处理大数据系统演化而来
- 源于实际应用增强实时性的需求
- 和批处理系统共存
- 系统设计理念和思路
- 抽象!抽象!!抽象!!!
- 先保证正确,再优化
- 通过高层语言提高可用性

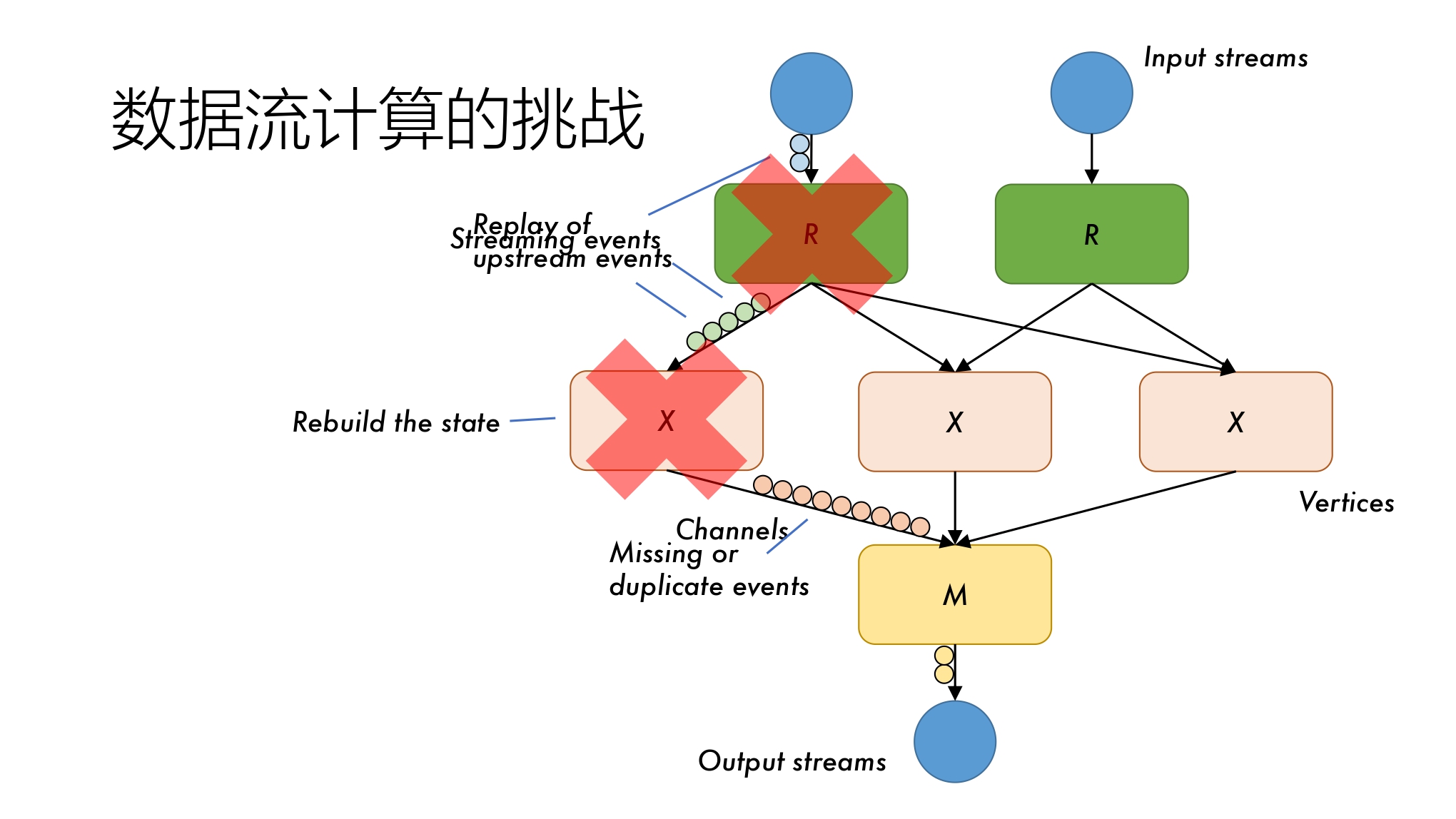
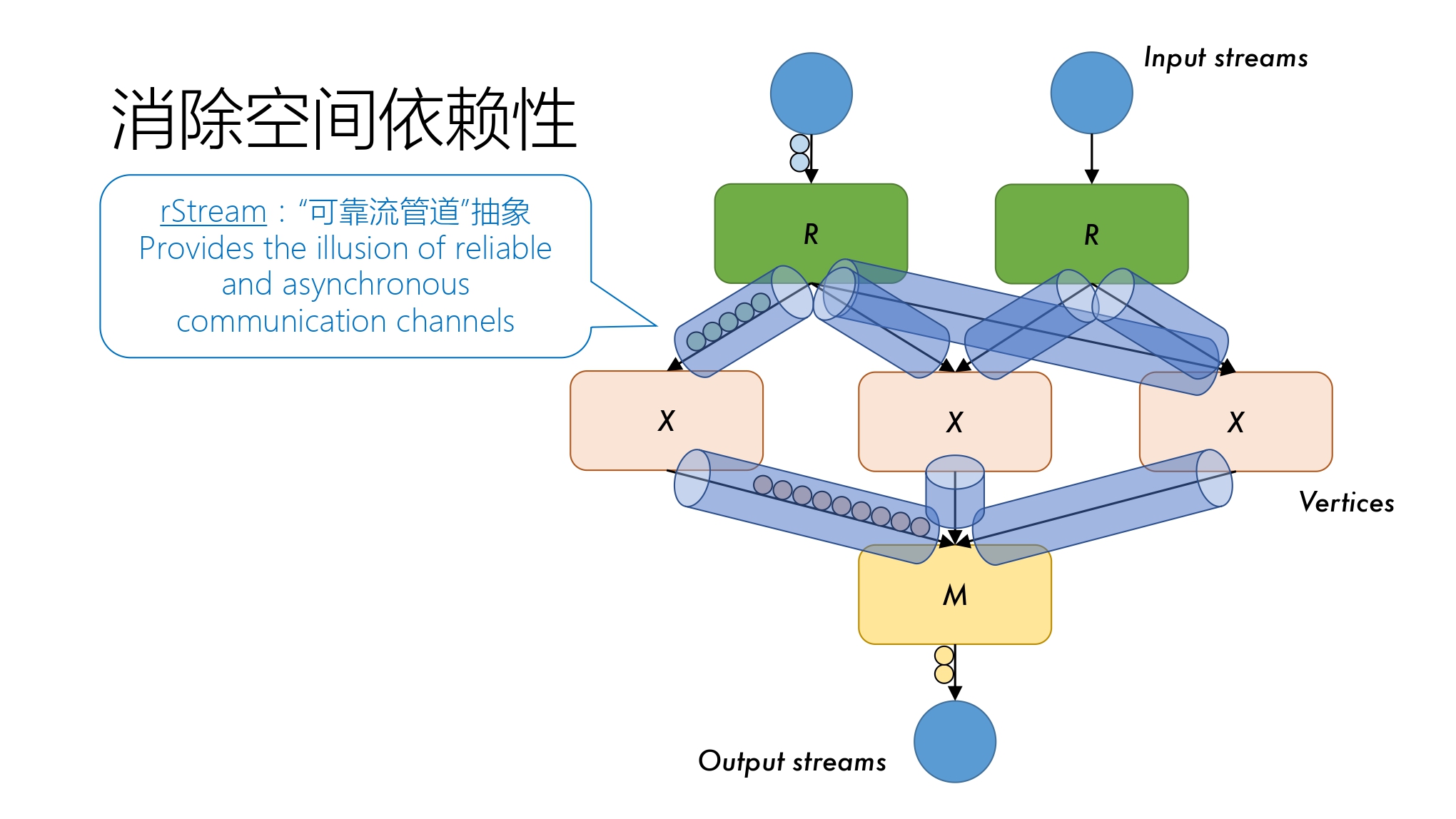
在流处理的过程中,由于是阶段->阶段的,考虑出错的常态化,如果某个节点出错,且采取 Rebuild State(重建状态)的策略,最坏情况可能需要 Ref 的节点也处于出错状态,这样数据就在 Data Shuffling 的过程中丢失了。为了消除数据前后的空间依赖性,有必要构建新的抽象。
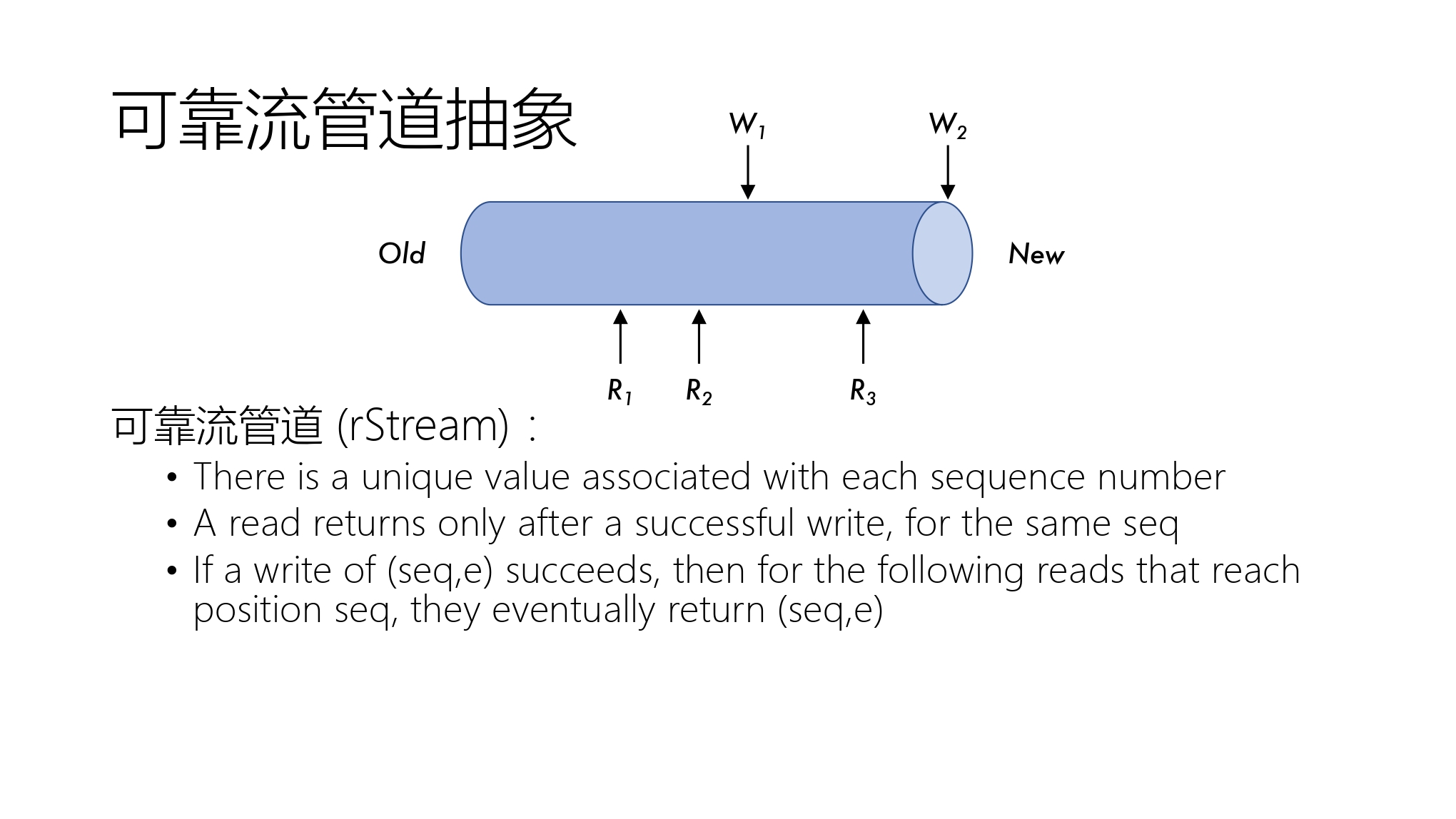
抽象 1 可靠流管道抽象
可靠流管道(rStream)
- 每个序列号码都有一个唯一值
- 对于相同序列号,必须成功写后才可以读
- 一个写操作\((seq,e)\)完成后,后续对该位置读都会返回\((seq,e)\)
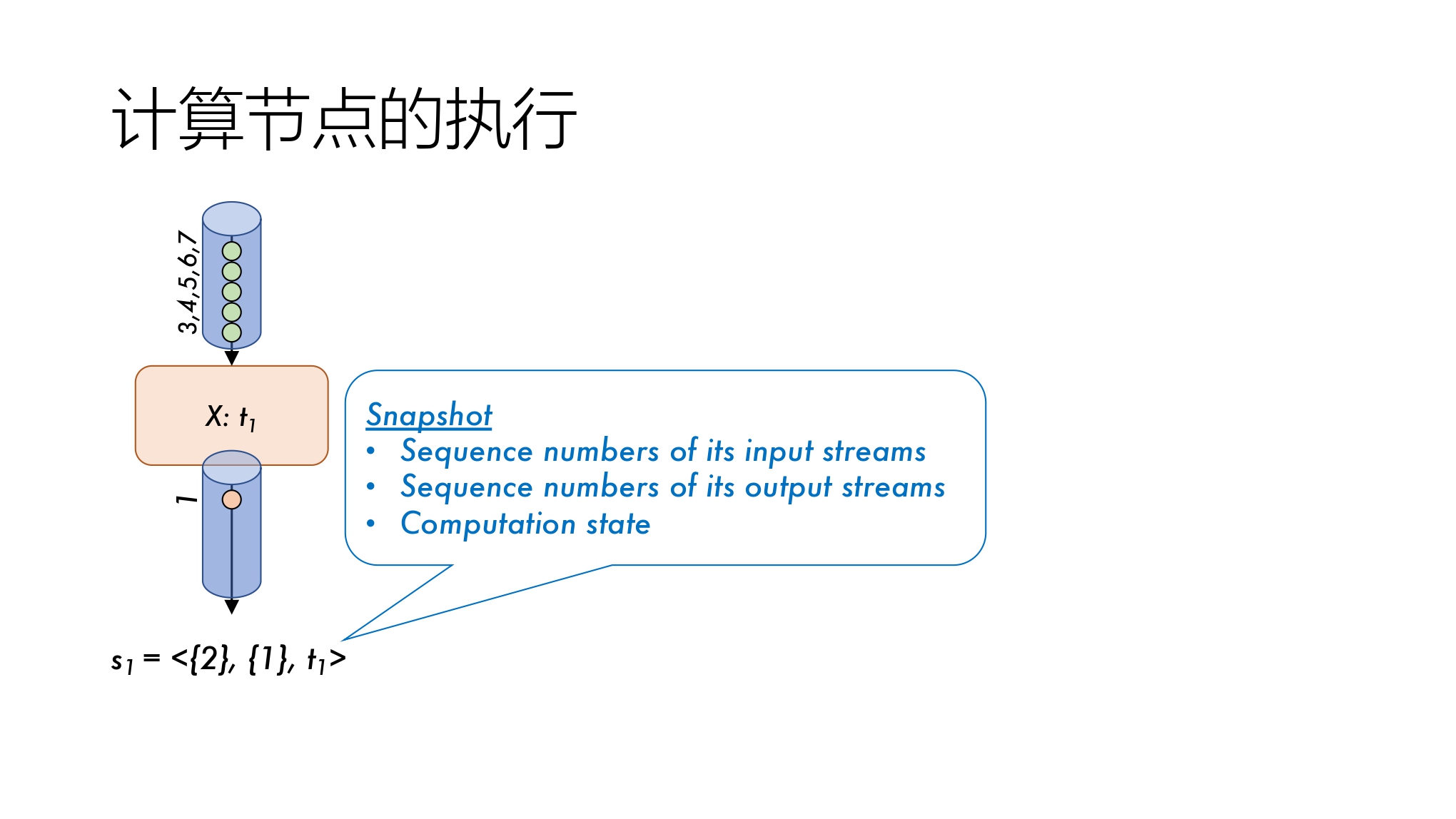
抽象 2 可恢复节点抽象
可恢复节点(rVertex)
以快照形式作为状态记录,包含三个属性值:
- 输入流序列号
- 输出流序列号
- 当前计算状态
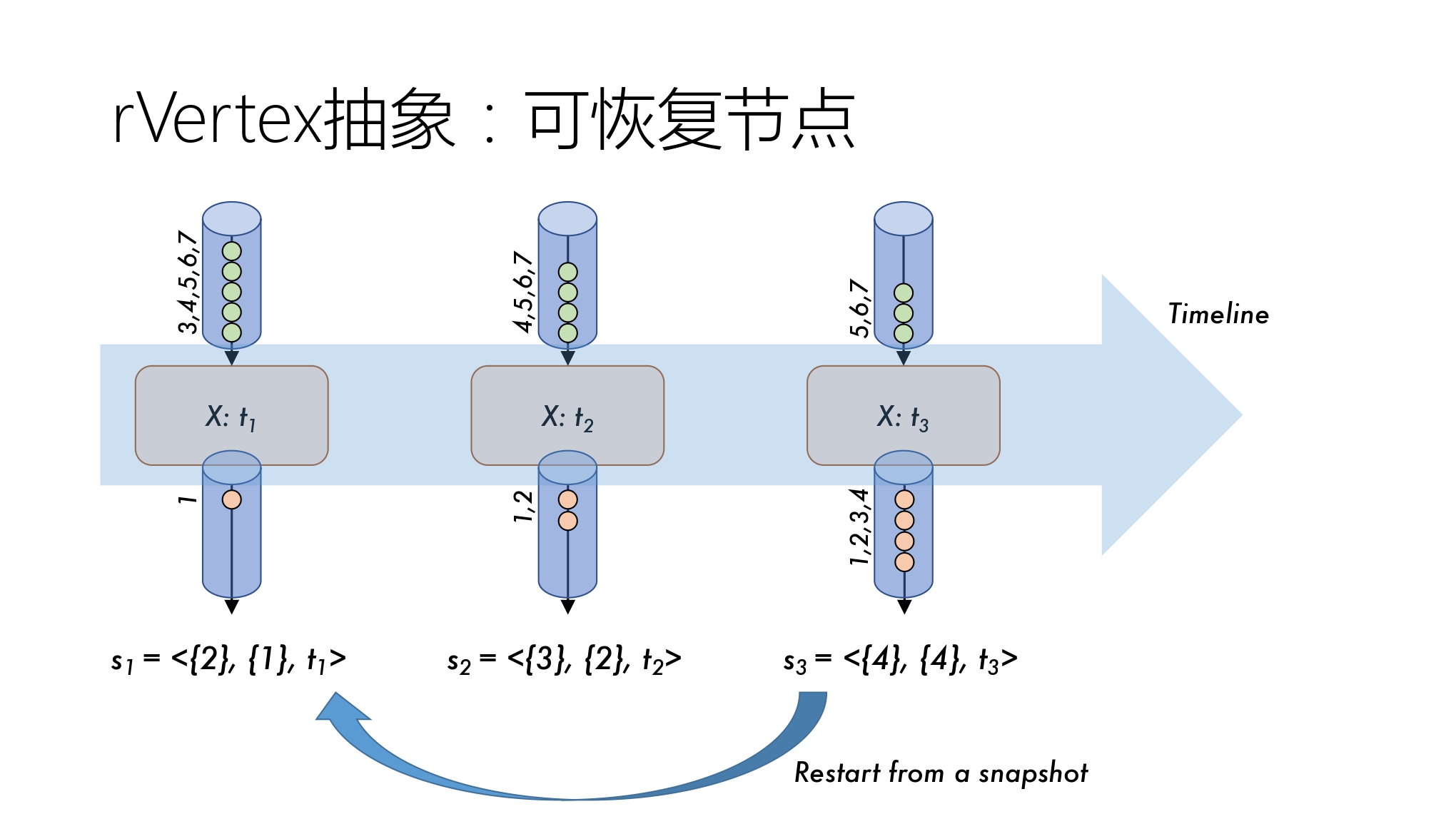
出错恢复:根据快照记录回到过去状态,对于输入流进行重询问,由于 rStream 抽象,先前成功得读再后续读会返回相同的值,从而使用此性质可以完成成功得重询问,实现出错恢复。
抽象,抽象,抽象
抽象的要求:自身要简单、易于理解。
合理的抽象使复杂的数据流可靠性和容错问题变得简单
- 一目了然的正确性
- 但是简单的实现是抵消的:需要同步写到高可靠存储系统
保持抽象,但使用一个混合高效的实现
- 把费时的写操作移出关键路径(critical path)
- 但仍保持可靠管道的性质
统一的抽象,不同的恢复策略选择
- Recomputaion using dependency tracking at runtime
- Checkpoint/log replay
- Persistent state/streams
- Hybrid
合理的抽象简化系统开发、维护、调试和部署,分布式流处理从此变得简单。在微软的实践中,在这两个抽象的帮助下,整体业务可以达到:
- 离线调试验证模式,无缝上线
- 支持在线对每个节点的单独调试
- 支持灵活的在线迁移和动态调整
- 对过去的执行片段的审计
- 系统维护过程中的无间断执行
审视人工智能系统的机会和挑战:From Big Data Systems to AI Systems
系统的两大重器:编译,架构
AI 蓬勃发展带来了新的方法论,比如,深度学习+:
- Deep Learning Compiler Optimization 深度学习编译优化
- Deep Learning Training Job Scheduing 深度学习训练任务调度
帮助上层应用更好的利用底层硬件技术革新的项目——卧龙计划(Project Wolong)。
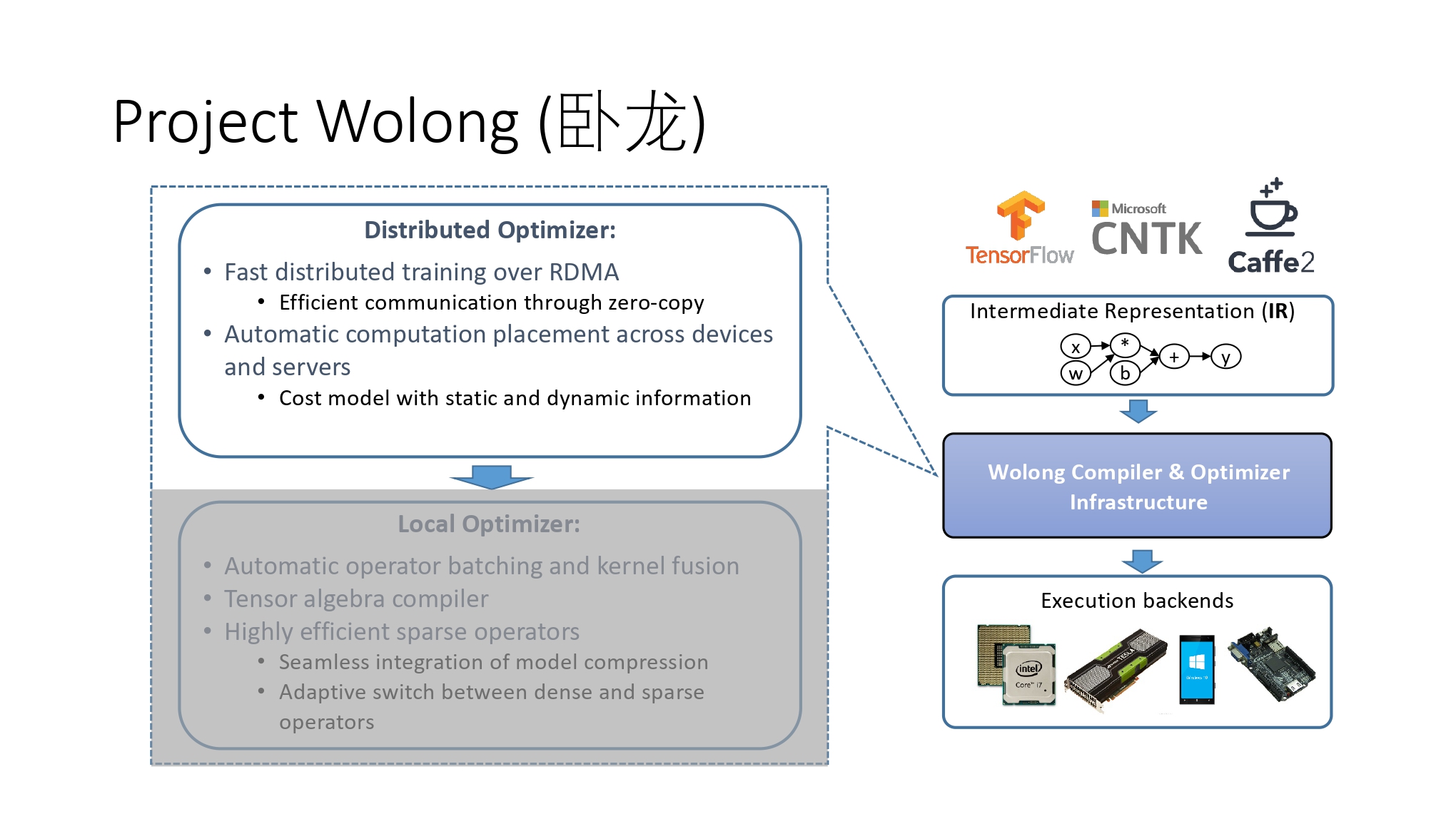
Project Wolong: Distributed Optimizer
基于 RDMA(Remote Direct Memory Access)的快速分布式训练
基于设备和服务器的自动化计算部署。
利用 RDMA 实现 Zero-copy 设备沟通以提高效率,应用在:RPC、GPU 加速
Project Wolong:Local Optimizer
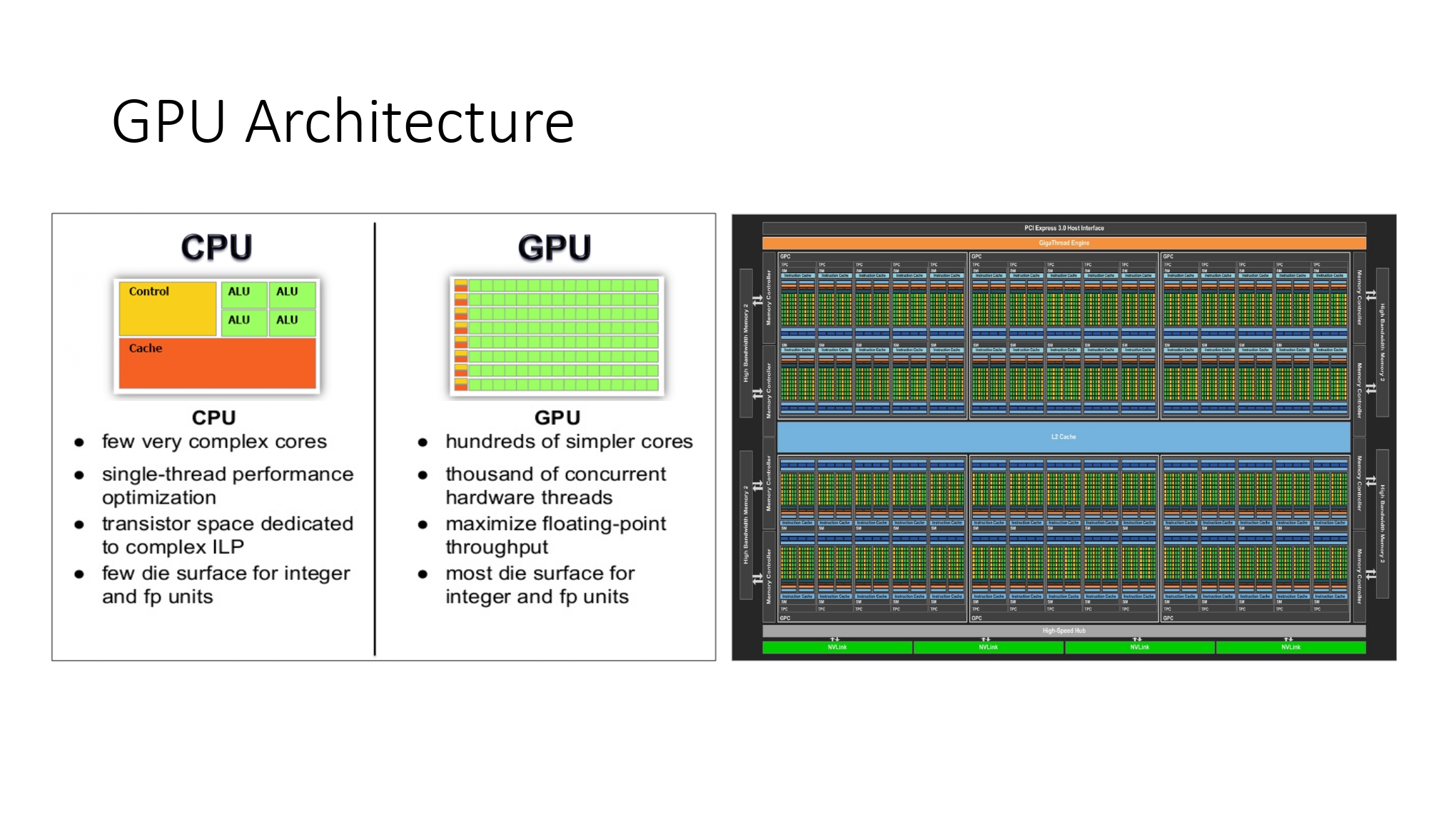
对比 CPU 和 GPU 的架构
| CPU | GPU |
|---|---|
| 少量的复杂核心 | 大量的简单核心 |
| 单线程表现 | 成百上千的硬件线程 |
| 晶体管空间致力于复杂的指令级并行(ILP) | 最大化浮点吞吐量 |
优化方向:Operator Batching and Kernel Fusion
运算符的抽象粒度较低,导致一个真实的训练模型的数据流图往往会包括数千个节点,这些节点在 GPU 上的执行就会变成数千次 GPU 上的内核执行。这些粒度较小的内核函数在提供了灵活性的同时,其频繁的调用也成为当前影响许多深度学习框架性能的一个重要因素,其带来的性能开销主要体现在:数据流图的调度开销,GPU 内核函数的启动开销,以及内核函数之间的数据传输开销。
解决这一问题的一个直接方法就是合并相同运算符操作和内核融合,以更好的利用 GPU 的并行特性。
关于内核融合的详细介绍:内核融合:GPU 深度学习的“加速神器”,薛继龙
但是 操作符 Batch 的自动化,以及核的融合并非想象中简单,存在一些技术上的难题:


最后整体的工作流:
- 图优化:硬件无关优化策略
- 检测融合子图:找到一些可被融合的图节点
- 代码生成:给定一个融合子图,生成相关内核函数代码
- 图修改:将融合后的内核所对应的 Operator 替换之前的子图,并插入原来的数据流图中
- 循环多次直至满足需求
实现产品NNFusion:一个多功能深度学习编译器。
Deep Learning Training vs. Big Data Processing
不考虑现在处理的问题和原来的问题有哪些不同,而照搬过去的方法是系统改良过程中一种不负责任的行为。
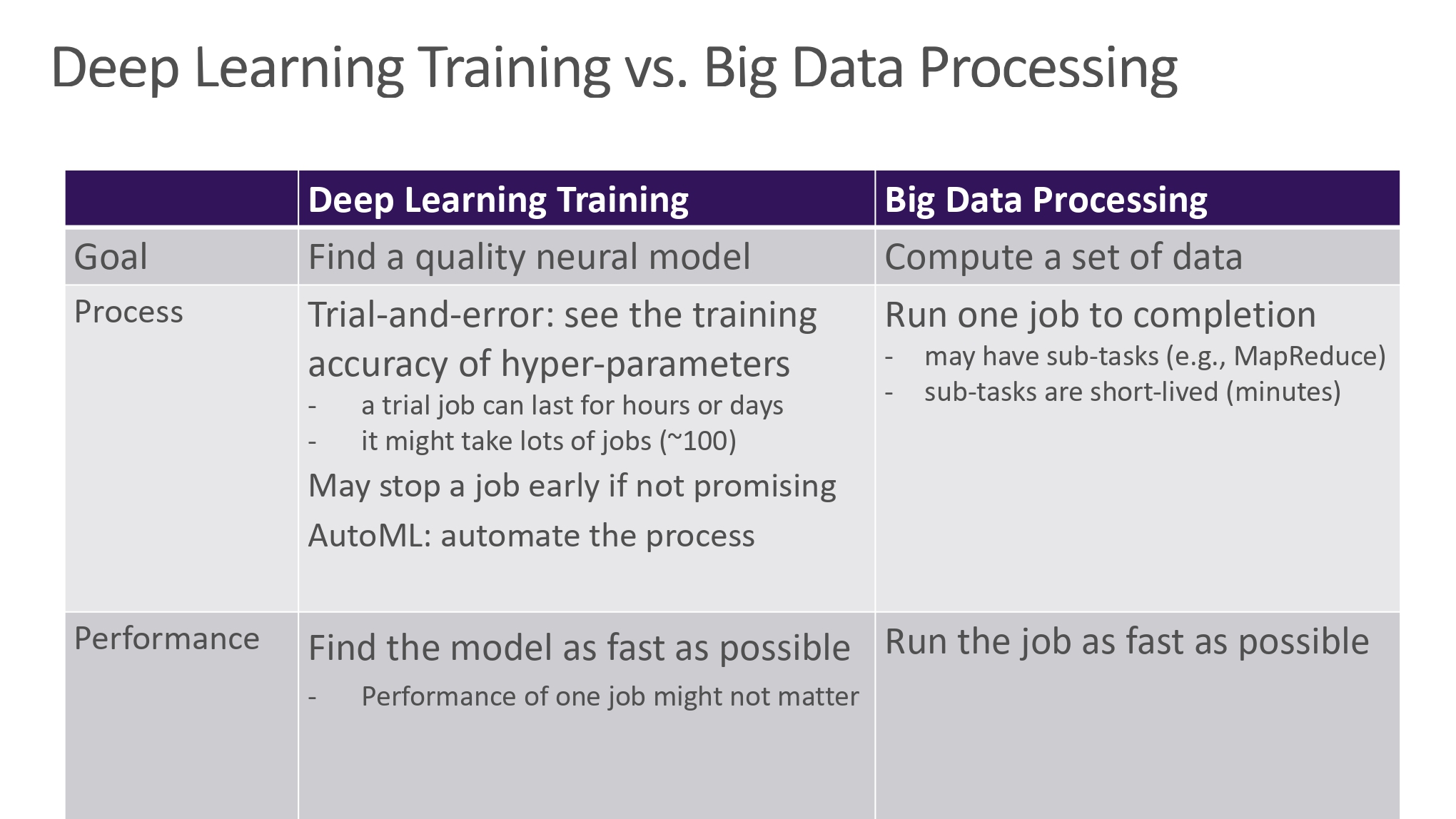
对比目标,过程,表现三方面的不同,我们获得的启示:
- 更多的并行工作会更好(The More Parallel Jobs the Better)
- 使长期工作适应不断变化的环境(Adapt the long-running job to the changing environment)
- 使深度学习进行时的微批处理(mini-batches)更加高效
结语
- 系统创新和优化时大数据和人工智能的以打击时
- 以独特的视角去发现和定义新的研究问题
- 综合全面系统地解决方法
- 大系统研究和创新的黄金时代
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!