CCFADL105——“智能在网计算”应用智能网卡技术加速数据中心
“智能在网计算”应用智能网卡技术加速数据中心
主讲人:谭焜(Phd,华为)

总览
network stack
IP 层往上,栈(协议栈)更贴近软件,IP 层往下,更贴近硬件。从软硬件均实现了 Network 的服务需求。
Bottleneck 的改变
| 过去 | 现在 |
|---|---|
| IP 层作为网络协议栈处在中心的位置,网络通讯速度相较于 CPU 和内存的速度来说要慢很多 | 网络速度以 200 倍到 2000 倍速度增长,而 CPU 计算增速却放缓,摩尔定律放缓 |
| eg: at 1990, Intel 80486 32bit@33MHz vs. ETH 10Mbps | eg: CPU 10~100GHz vs. ETN 400 Gbps |
内存增长也遇到瓶颈
完全吃下 40G ETH, 8 TCP conns 网络数据至少需要 5 核。
问题
Question: How to scale networking with ever growing speed?
如何应对加剧增速的网络?
Answer: making network smart!
让网络变得“聪明”:
SmartNIC: intergrating general programmability into network interface card.
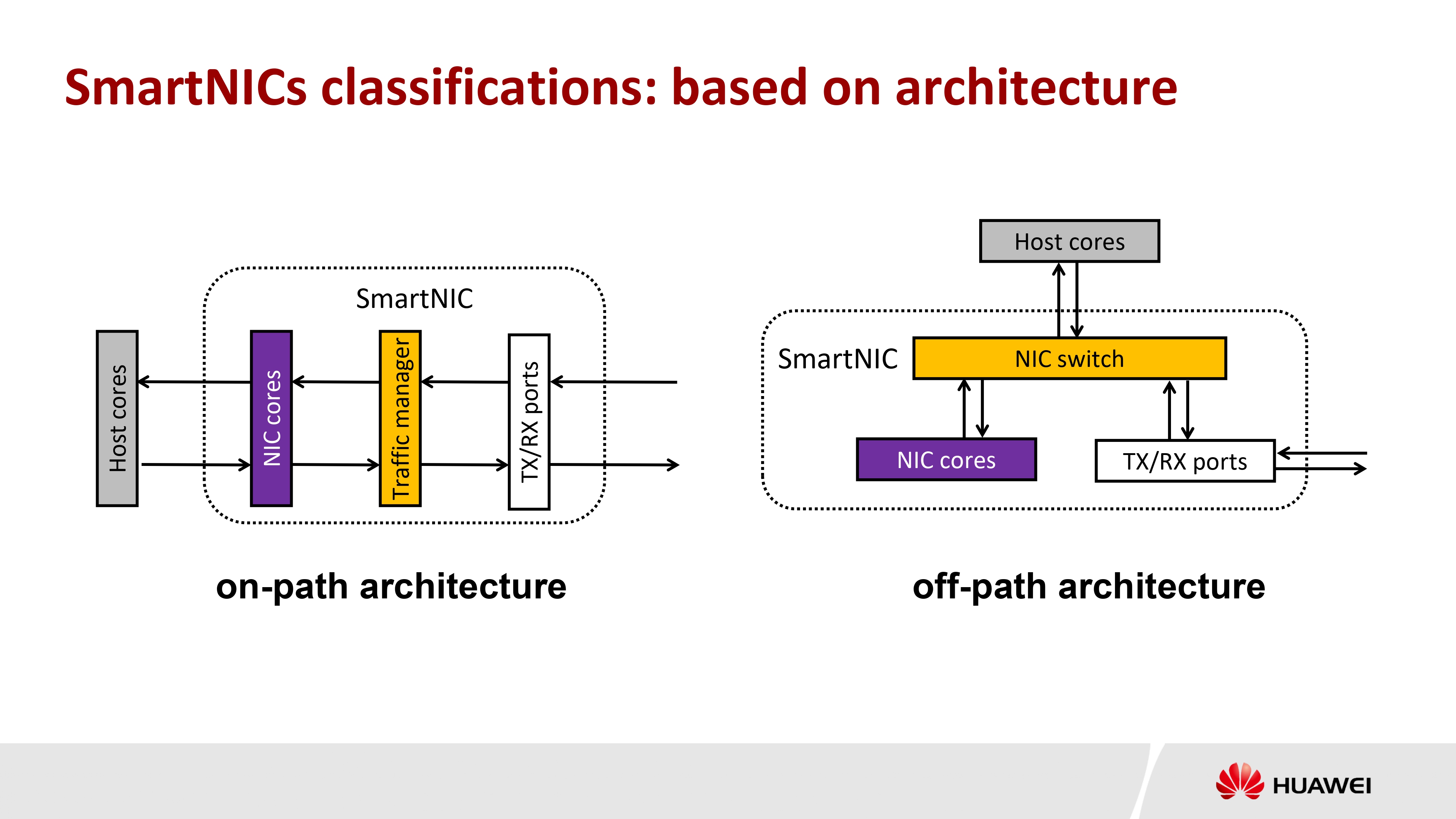
SmartNIC 分类
对于 SmartNIC 的分类,可以从架构和核类型两种角度进行分类:
- 按架构(Architecture)分类
- on-path(SmartNIC 核在路径上,网络传输必须必然经过)
- off-path(SmartNIC 核在旁路上,网络传输可通过 Swith 不经由)
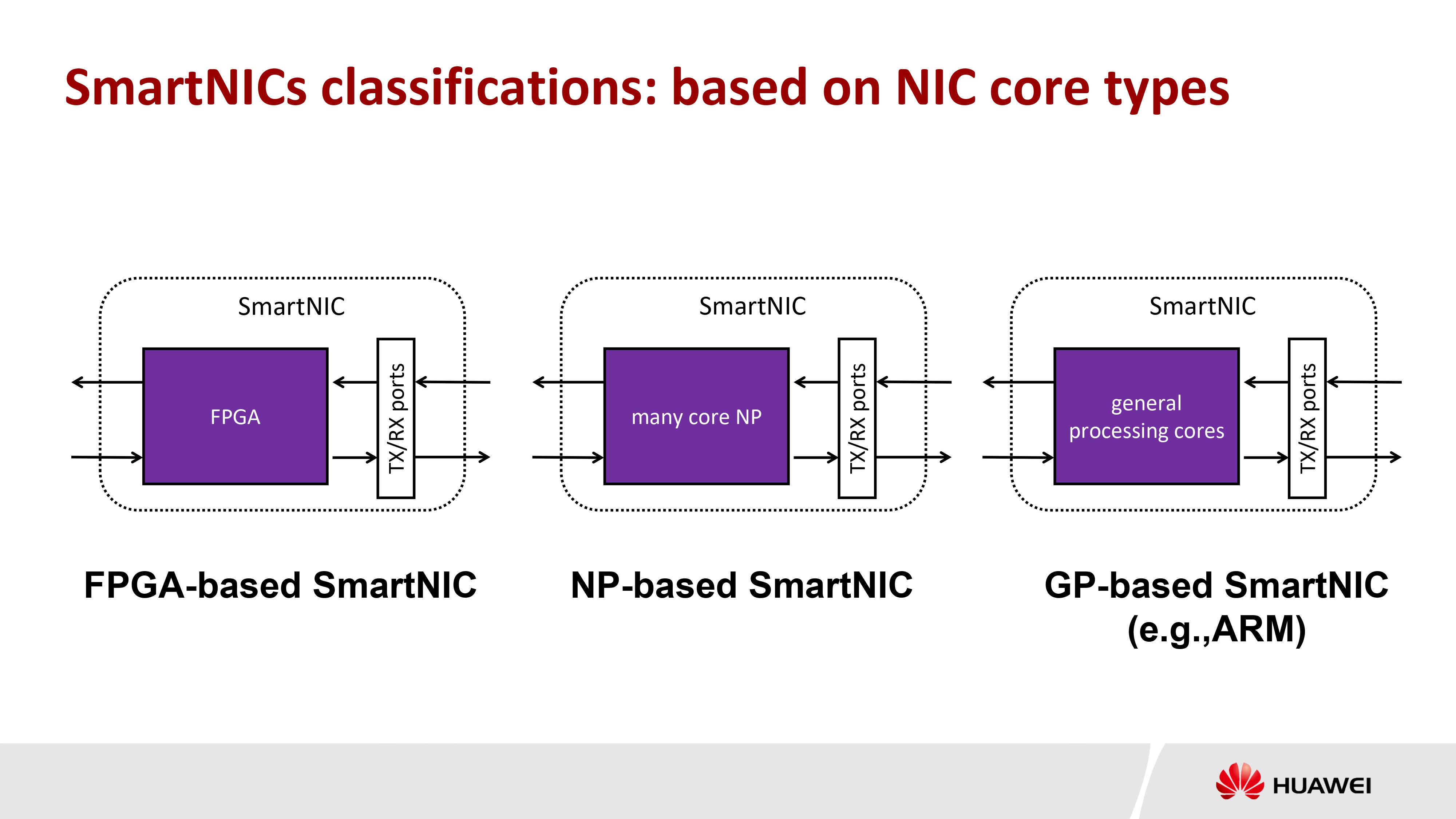
- 按核类型(core types)分类
- FPGA-based 基于 FPGA
- NP-based 基于多核 NP
- GP-based 基于通用处理器核
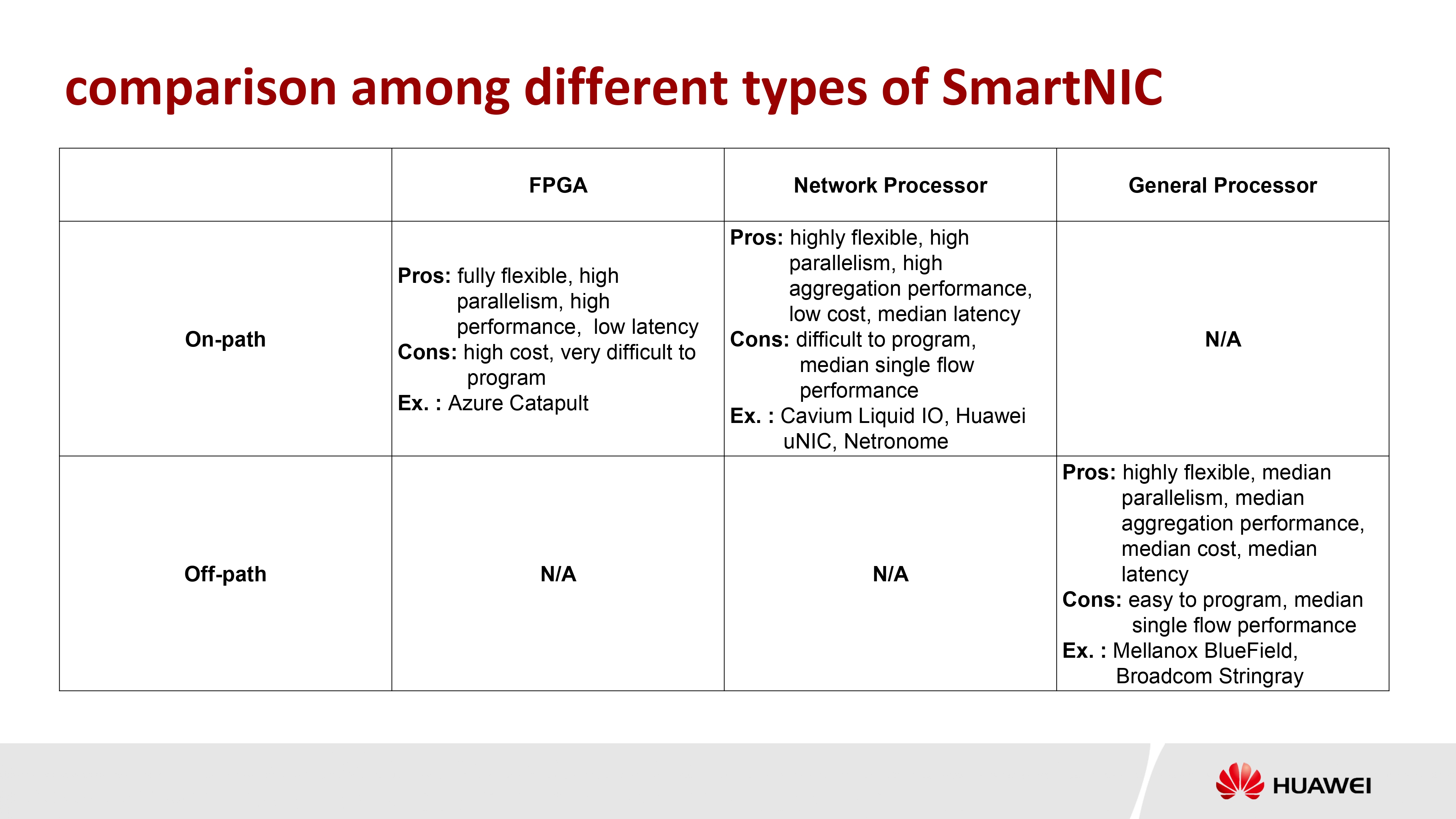
业界多种选择
- Microsoft FPGA-based SmartNIC
- Cavium/Marvel NP-based SmartNIC
- Huawei NP-based uNIC
- Mellanox ARM-based SmartNIC
SmartNIC 编程
硬件编程困难,需要考虑时序度、DMA 等等。
Make it easy.
ClickNP
- 如同在多核处理器上编程
- Element 单元作为单线程的 core
整个体系结构,通过 ClickNP compiler 把运行库和所写程序编译,生成对应 Host 宿主机 CPU 执行的 C 代码,和在 FPGA 上执行的代码。
iPipe
- Actor 模型,Actor 调度
- 最大化 SmartNIC 的利用
- 调度策略:混合调度(Hybrid Scheduler)
- SmartNIC,必要时调度到 CPU
- 动态
eg: 根据报文大小采取的动态 SmartNIC 的策略。
eVS offloading with Huawei uNIC
云计算中的 Private Cloud,云计算 Deloy 很多的服务器,其生意模式是将机器租用给租户,如下图(蓝、绿、红),每个用户建立一个虚拟化的网络,客户角度看就是一个私有网络(像是真正的物理网络一样)。
通过虚拟交换机,发送时 vSwitch 在原来的报文上再打一个标签,再发送到实际的物理网络上,接收的时候对应不同的报文标签再分给不同的 VM。
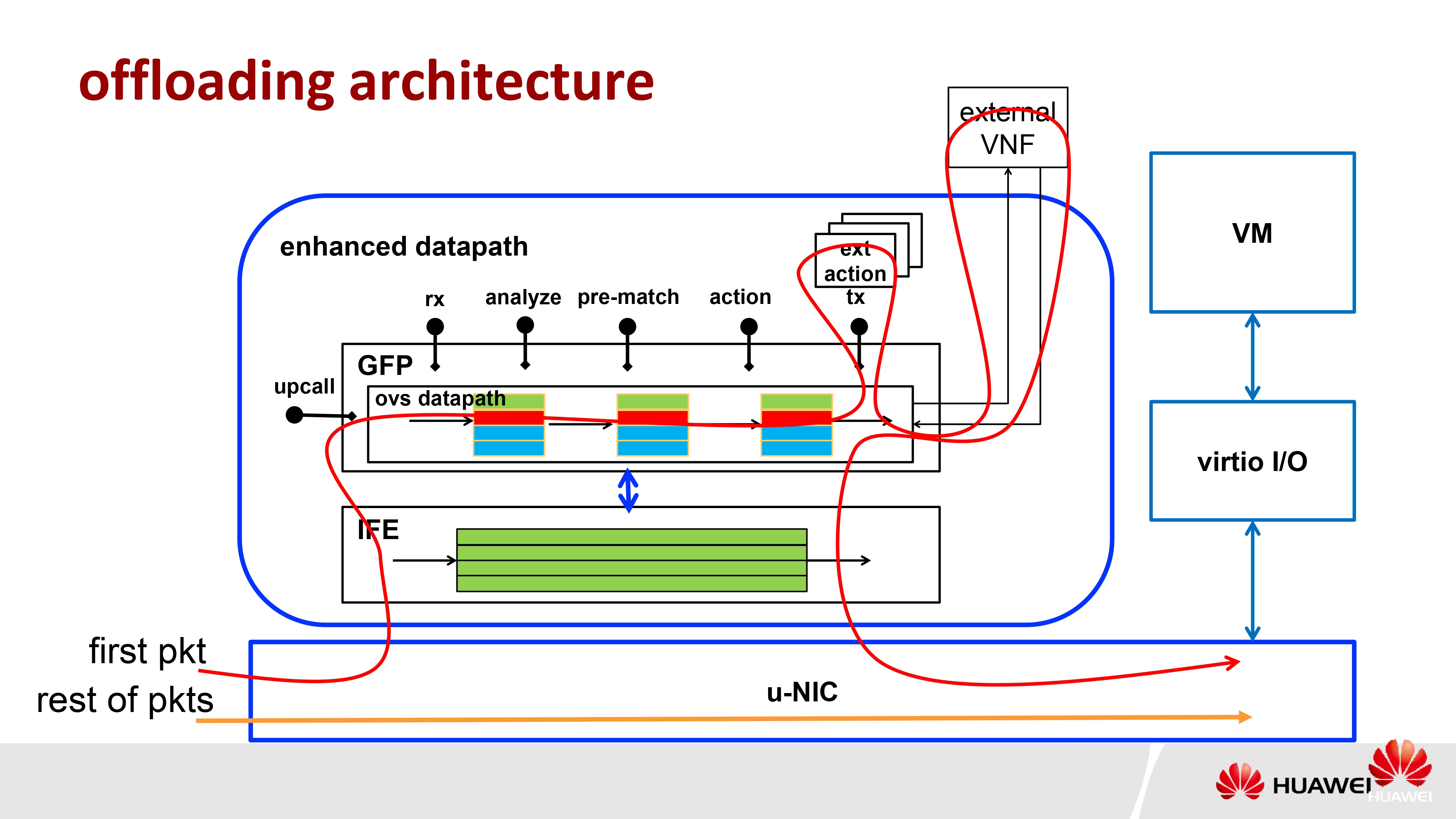
对于一个完整交换的过程(流表),完全让智能网卡照搬解决,1.不显示,2.和让宿主机 CPU 处理器没差别。
解决:缓存固定的流数据的结果,first pkt 与 rest of pkts 区分开,通过缓存加速 rest of pkts。
实现:在智能网卡中做个 Cache,相同报文头的固定结果缓存到 Cache,后续网络包查表加速。
Multi-path RDMA Design
- kernal bypass and transport offloading(内核旁路以及无负载传输)
- 不为 CPU 增加负担,降低延迟并且提高吞吐量
- existing RDMA has only a single path transport(现有 RMDA 单路径传输)
- fail to exploit multiple paths capability of modern DCN for reliability and load-balance(未能利用现代 DCN 的多路径能力来实现可靠性和负载平衡,协议缺失)
目标:为 RDMA 构建一个 multi-path 多路径传输
设计挑战
Challenge 1. 如何在不知道每个路径状态的情况下实现拥塞感知流量分割
Solution 1. multipath ack-clocking
Challenge 2. 如何跟踪具有微小和恒定内存的无序数据包
Solution 2. out-of-order aware path selection
Challenge 3. 如何在保序的同时通过多路实现性能增益
Solution 3. explicit sychronise operation
multipath ack-clocking
设计内涵:
返回 ACK 隐含拥塞信息
算法:
- \(N\)条路径上发送\(N\)个包
- 为所有路径保留一个拥塞窗口(cwnd)
- 对于每个返回的 ACK,只有当 cwnd 允许的时候,将数据包输送到路径上
out-of-order aware path selection
设计内涵:
选择具有相似 延迟的路径
算法:
\(snd\_ooh\),人工设定一个参数\(\Delta\),\(snd\_ool = snd\_ooh - \Delta\),包落在这个时间区间内的,都是 Good Paths
sychronise operation
这个没太懂,加标签?
MPTCP vs. MPRDMA
为什么选择构建新的 MPRDMA:
对于 MPTCP 来说,对于每一个 Single Path 都要去维护一组状态,实践中导致整体状态值很大,难以实现在硬件中,所以考虑从新设置一种适合的模式,减少 State 数,使其不随 Path 的增加而增加,便于硬件实现。
KV-Direct

后续都是基于 KV-Direct 论文,讲真,谭教授讲的有些快,后续有时间再补。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!