OSDI20——Testing-Database-Engines-via-Pivoted-Query-Synthesis
Step 1
题目摘要引言
Title
Testing Database Engines via Pivoted Query Synthesis
通过 Pivoted Query 方法来检测数据库引擎
Abstract
DBMSs 的检测,fuzzers 被广泛永安里检测 crash bugs,但是针对 logic bugs 的通用方法一直是空白。
提出一种 novel and general 方法,Pivoted Query Synthesis.
核心方法:去随机拿去 pivot row....
Introduction
基于关系模型的 DBMSs 是许多应用的核心组件。关于其检测工具,较为出名的有SQLsmith,可以探测导致 crash 的异常。以及模糊检测工具 Fuzzers 比如 AFL,也被 DBMSs 日常应用。但是这些方法都无法检测 logic bugs。
关于 Fuzzing
模糊检测是识别实际软件中安全问题的最强大,最成熟的策略之一。 它负责迄今为止在安全性至关重要的软件中发现的绝大多数远程代码执行和特权提升错误。
不幸的是,Fuzzing 比较浅显: 盲目的,随机的变异使得极不可能到达测试代码中的某些代码路径,从而使某些漏洞牢不可破。
logic bugs 难以自动化探测。
- key challenge:找到 test oracle,能告知一个系统根据指定输入,是否表现正常。
- prior work:differential testing 方法,在多个 DBMSs 执行相同一段 test oracle,并对比输出的不同。实现工具:RAGS,局限:尽管 DBMSs 都使用 SQL,但都对标准进行扩展,并在一些部分不尽相同,因此在不同 DBMSs 实现完全一致的语义很困难。
本文的方法:
- Pivoted Query Synthesis (PQS)
- 实现工具:SQLancer
- 核心思路:randomly-selected row(pivot row),组织查询,使得其结果必须包含该 pivot row。

以 Listing 1 为例,通过该方法发现了 13 年起就存在的 critical bug,而且简单的例子在不同的 SQL 中实现也不尽相同。3 种 DBMS 都实现了 IS NOT TRUE,但是语义不同,对于 SQLite,仅 fetch value 0,而不会产生如 Listing 1 的 bug。
limitations: 只能部分验证查询结果,对于聚合函数,结果集的大小或是顺序,不能查验。此外,实施该技术所需的工作量取决于要测试的操作的复杂性,这对于复杂的操作符或功能而言可能会很高。
contribution:
- 高效的查找 bug 方法:PQS
- 工具:SQLancer
- 一份评估
Background
Database management systems. aim to test relational DBMSs (based on relational data model)
\(R \subseteq S_1 \times S_2 \times \cdots \times S_n\),\(S_1,S_2,\cdots,S_n\) are referred to as domains. More commonly, a relation is referred to as a \(table\) and a domain is referred to as a \(data ~ type\). Each tuple in this relation is referred to as a row.
Test oracles. An effective test oracle is crucial for automatic testing approaches. A test oracle assesses whether a given test case has passed. Manuaaly written test cases encode the programmer's knowledge who thus acts as a test oracle. In this work, we are interested only in automatic test oracles, which would allow comprehensively testing a DBMS.
Tested DBMSs. Focused on three popular and widely-used open-source DBMSs: SQLite, MySQL, and PostgreSQL. They are among the most popular and widely-used ones.
基本理论概况
结论部分
介绍了一种用于探测 DBMSs bug 的新方法,PQS,并且实现了 SQLancer 工具,据此在三个最流行的 DBMS 种找到至少 96 个 bug。当前仅实现了功能描述的一个子集,剩余可能作为后续研究。
PQS 的一个缺点是需要针对每个要被测试的 DBMS 进行实现,未来工作,可能通过提供共同的构建模块(common ?)来减少这种工作。
PQS 可以拓展为(取反),比如对其值要求为 Fasle 或者 NULL,但却错误地提取到 pivot row(应该是提取不到的)。
回答基本问题
类别
测试类
内容
暂无
正确性
真实有效,有应用并找出实际的 bug。
创新点
pivot row 来自动化寻找 logic bugs
清晰度
清晰
阅读选择
继续阅读
Step 2
细读笔记
Pivoted Query Synthesis
核心:随机选取 pivot row,随机生成一组布尔谓词,对它们进行修改使得基于 AST 的解释器求值为真。将其放置在 WHERE 和 JOIN 后,表达式(子句)为真使得该 pivot row 必然会被选择到。如果没有则说明探测到 bug。
testing oracle,依赖 AST 解释器。作者同时解释了,可能对于复杂的操作符(如正则)有一定的实现复杂度,但是可以避免其他 DBMS 设计中的苦难,也不会影响工具的性能。
Overview
Figure 1 展示了细节流程
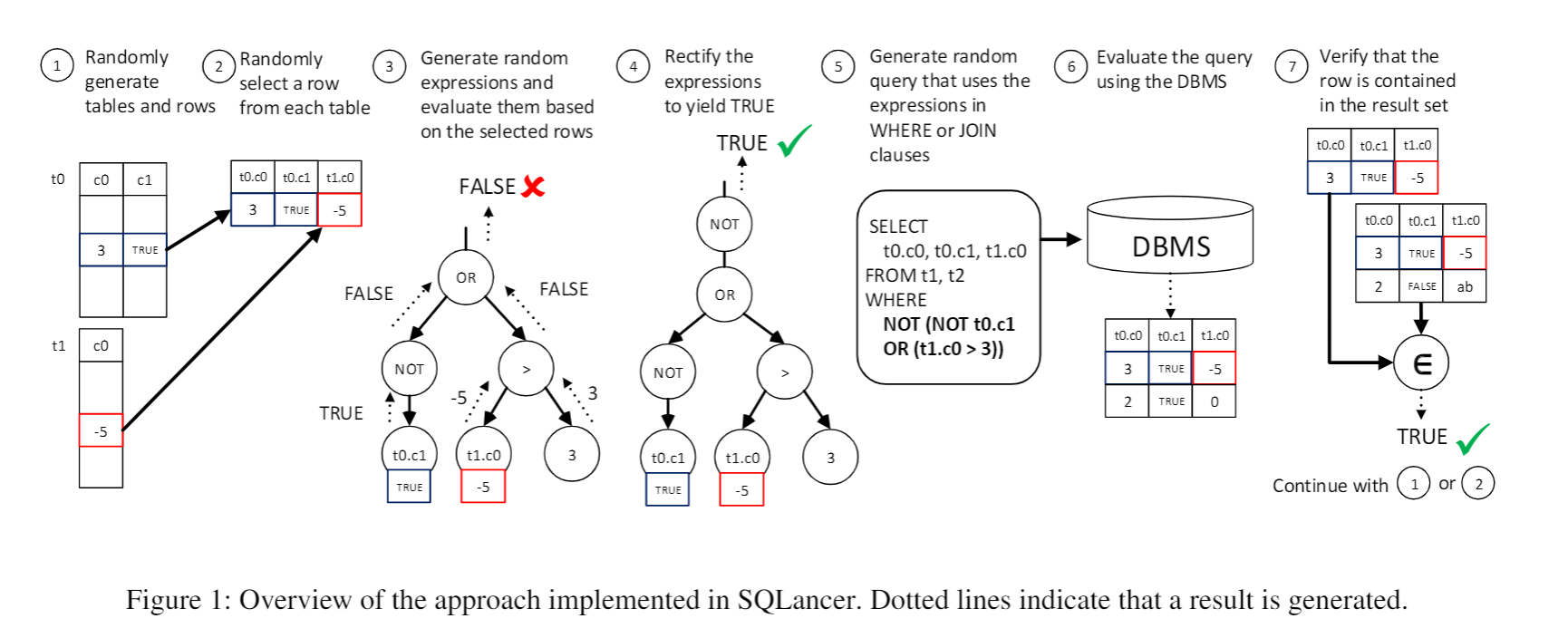
循环可以从 Step 2,开始重新随机挑选一个 pivot row,或者从 Step 1 开始重新构建 database。
core idea is given by how we construct the test oracle (Step 2 -> Step 7).
Query Generation & Checking
解释如何生成随机的谓词,纠正并在查询中使用 (Step 3 -> Step 5)
Random predicate generation. 根据 database schema (列名和类型)构造达到指定深度的 AST。根据层数选择是否允许在随即类型中加入一元、二元等运算符,这样就可以控制层数。
Random expression generation 不是本论文的贡献,random query operation 里斯 RAGs 和 SQLsmith 中都有实现。
根据 DBMS 的 SQL“方言”文档,手动实现了表达式生成器。
Expression evaluation.
check TRUE. 每一个节点必须提供 \(\mathsf{execute()}\) 方法来计算节点的结果。 Leaf nodes directly return their assigned constant value. Column nodes are assigned the valuethat corresponds to their column in the pivot row.

AST interpreters 要比 programming language 要简单很多,因为所有的节点都是字面值(换言之,不需要考虑可变存储)。bottleneck,DBMS 如何计算值,而不是 SQLancer,比如 LIKE 正则表达操作符,要超过 50 代码行 in SQLancer
Expression rectification.
值的矫正,Step 4 需要保证最终值为 TRUE。SQL 基于 TRUE,FALSE 和 NULL 三值逻辑。为了使最终结果为 TRUE,使用 Algorithm 3.
类似一个简单的修复,如果预期使 TRUE 的,那么就是我们最终想要的表达式,直接输出\(randexpr\),如果是 FALSE,则在前面填充一个 NOT 一元操作,如果是 NULL,则\(randexpr ~ ISNULL\)
Query generation
Step 5,用于 WHERE 子句,保证 pivot row 在查询的输出中,以及用于 JOIN 子句,使得连接表格后,pivot row 出现在结果集中。
Checking containment
检测 pivot row 是否出现在结果集中是最后一部。构造查询,将 Step 6 和 Step 7 组合在一起,DBMS 提供了一些运算符来检测“包含”,比如 IN 和 INTERSECT。

Random State Generation
回过头来讲 Dababase 状态的构造。
第一步是使用 CREATE TABLE 陈述构造表,后续陈述是启发式的。
这一部分 The random database generation 也并非本文的贡献,很多方法都已被提出,并且可以与 PQS 相配合。
问题记录
未读(且值得读)文献记录
Step 3
思路复现
PQS Implementation Details
本节主要解释了实现部分的决策。
Error handling
理想:语法+语义都正确。但是语义正确很难达到,比如说对于唯一值的要求。如果要满足语义正确需要附加的检测机制,权衡下,通过 Error message 反馈出来。
Performance
每个线程跑独立的 database(Step 1 生成)。为了充分利用每个 CPU,我们降低了生成导致 CPU 利用率较低的 SQL 状态语句的可能性(例如 PostgreSQL 中的 VACUUM)。通常,SQLancer 每秒生成 5,0000 至 20,000 条语句,具体取决于正在测试的 DBMS。 由于我们测试的 DBMS 比其他语句快得多,因此 SQLancer 为每个数据库生成 100,000 个随机查询。
Number of rows
大多数 bugs 通过限制 rows 为较低数目(10-30)时找到。太多数目可能由于不受限制的表连接而使得行数进一步爆炸。
潜在的问题是,这可能会阻止 PQS 检测仅针对具有许多行的表触发的错误。 作者认为未来的工作可以通过限制查询结果的基数来解决此问题
Evaluation
Setup
laptop
6-core Intel i7-8850H 2.60GHz
32GB memory
System: Ubuntu 19.04
DBMS versions: latest release version
SQLite 3.28(trunk version)
MySQL: 8.0.16-17
PostgreSQL: 11.4(Beta 2 version)
Baseline
没有使用的基准,RAGS 时 20 多年前提出的,而且没有公开。SQLsmith,AFL 和其他随机查询生成工具与模糊检测工具,只探测 crash bugs,这一子集可能与 SQLancer 探测的 crash bugs 有重叠,但这并不重要。
证明与推理复现
实验验证复现
bug 的文章,都是以bug report来表示的,并不是性能图标。这才是重点!!!!!
三个图标,从左到右要求递增
- available:开源的
- functional:可用的
- reproduced:开源的代码能再现文章的内容
找到别人的没找到的很重要!
这个区分logic bug很重要,说明工作的重点体现出来了。
scalability 的问题
VLDB里面很多paper,抓取SQLite语句进行分析,通过重写SQL,提升性能?
evaluation是重点!简单的idea能找到很多bug对于本身来说是加分点!
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!