Go学习——《Go语言程序设计》Chap5
过程式编程
我学习的主要关注点是 Go 语言的并发编程,而过程式编程是并发编成和面向对象编程的基础,这一节主要细致探究过程式编程中的一些问题(语句控制结构、自定义类型和函数等)
语句基础
形式上 Go 语言语法需要分号,但是编译器帮我们完成了这项任务,在以字母字面量、字符串字面量、右括号系列、一些特定关键字和增建操作符结尾的非空行末尾自动加上了分号。
两个地方必须使用分号:
- 一行中放入一条或者多条语句
- 原始 for 循环
自动插入分号的一个重要结果是一个左大括号不能单独成行(变相限制了代码风格),比如下面这个就是不可通过编译的
1 | |
内置函数
除了之前见到较多的append(),len(),cap(),make()等,要着重关注学习异常相关的两个内置函数:
panic(x)抛出一个运行时异常,其值为 x。recover()捕获一个运行时异常。
快速声明操作符
快速声明操作符号:=用于同时在一个语句中声明和赋值一个变量。多个逗号分割的用法和=赋值操作符一样,需要强调的是,其本身不会新建作用域,即除了必须至少有一个非空变量为新的,如果变量已经存在了,它就会被直接赋值,而不会新建一个变量,除非该:=操作符位于作用域的起始处,如if或者for语句中的初始化语句。
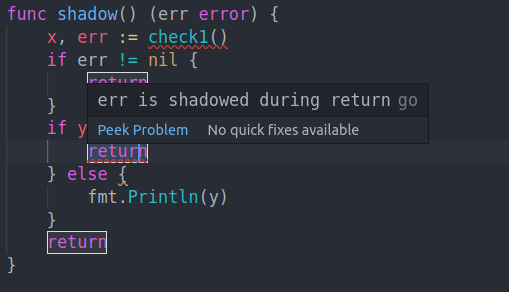
:=可以创建“影子”变量覆盖外层同名变量的值,这很方便,但在有些地方可能会引起失误和问题。
我们可以在有一到多个命名返回值的函数中写无需返回值的裸 return。这种情况下,返回值将是命名的返回值,它们在函数入口被初始化为其类型零值。
如果出现了返回值同名“影子”变量且涉及到 return,好在 Go 编译器会给出一个错误消息,正如下面这个样子。
类型转换
转换语法
1 | |
非数值类型之间的转换不会丢失精度,但是数值类型之间可能会。
类型断言
方式有安全/非安全(抛出异常)两种
1 | |
if+类型断言赋值给同名变量(影子变量)很常见,如果目标类型可以是很多类型之一,我们可以使用类型开关。
分支
if 语句
Go 里面的经典用法:
1 | |
放在 if 语句中的optionalStatement作用于整个 if...else...if 语句,也限制于其中。
switch 语句
Go 语言中有两种类型的 switch 语句:表达式开关(expression switch)和类型开关(type switch)。表达式开关语句对于 C/C++/Java 程序员来说比较熟悉,然而类型开关语句是 Go专有的。
需要强调的是,不同于 C/C++/Java,Go 语言的 switch 语句不会自动地乡下贯穿(因此不用每个 case 后面都加 break),相反,我们可以在需要的时候通过显式地调用 fallthrough 语句来这样做。
表达式开关 紧凑经典实用举例:
只使用一个表达式,一个带返回类型的函数,然后用逗号分割相同操作的不同 case(而舍弃用 fallthrough 贯穿写)。
1
2
3
4
5
6
7
8switch Suffix(file){
case ".gz":
return GzipFileList(file)
case ".tar", ".tar.gz", "tgz":
return TarFileList(file)
case ".zip":
return ZipFileList(file)
}字符开关 与类型断言相似,但是使用
type关键字代替实际类型,以用于表示任意类型1
2
3
4
5
6
7
8
9
10
11
12
13
14switch x.(type){
case bool:
block1
case float64:
block2
case int,int8,int16,int32,int64:
block3
case nil:
block4
case string:
block5
default:
block6
}经典应用,反序列化一个内部结构未知的原始 JSON 对象,并创建和打印 JSON 对象的字符串表示。
for 循环语句
for 和 for...range,记住 Go 的循环全是 for,包括但不限于
- for{} -> while(1)
- for Expression -> while(expression)
- for k,v := range() -> for k,v in ...
通信和并发语句
通信与并发特性在第 7 章详讲,这里描述基本语法。
goroutinegoroutine是程序中与其他goroutine完全相互独立而并发执行的函数或者方法调用。每一个 Go 程序都至少有一个,即 main 函数中运行的。goroutine非常像轻量级的线程或者协程。它们可以被大批量地创建。所有的goroutine共享相同的地址空间。同时 Go 语言提供了锁原语 🔓 来保证数据能够安全地跨goroutine共享。然而,Go 语言推荐的并发编程方式是通信,而非共享数据。创建方式
1
2go function(argu) // 调用已有的函数
go func(parameters) { block } (argu) // 调用一个临时创建的匿名函数被调用函数执行会立即进行,但是是在另一个
goroutine上执行,并且当前goroutine(包含 go 语句的)会从下一条语句中恢复。通信
通过通信管道实现多个
goroutine之间通信(发送接受数据)。发送分为阻塞发送 (channeel <- value)和非阻塞发送(select实现)创建通道的方式
1
2make(chan Type) //未指定容量,同步
make(chan Type, capacity) //指定容量,异步。我的实验代码,实验结果输出至 testoutput.txt,发现每次运行,输出顺序不一致,可以体现不同
goroutine的相对独立。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// createChannel 接受一个int类型的参数,返回一个int类型的通道
func createChannel(startInt int, chanName string) chan int {
next := make(chan int)
// 建立新的goruntime
go func(i int, name string) {
for {
next <- i
fmt.Printf("Channel %8s is now adding number %d\n", name, i)
i++
}
}(startInt, chanName)
// 由于chan是引用类型,所以返回以后在子goruntime还会继续运行
return next
}
func main() {
counterA := createChannel(8, "ChannelA")
counterB := createChannel(108, "ChannelB")
for i := 0; i < 20; i++ {
a := <-counterA
fmt.Printf("(A->%d, B->%d)\n", a, <-counterB)
}
}select语句,在一个select语句中,如果发现任意一句可以继续执行(没有被阻塞),则选择。如果全部通道都被阻塞,有 default 则执行并从select后恢复,否则整个语句阻塞,直到一一句可以继续执行。
defer、panic 和 recover
defer 语句用于延迟一个函数或者方法(或者当前所创建的匿名函数)的执行,它会再外围函数或者方法返回之前但是其返回值计算之后执行。这样就有可能在一个延迟执行的函数内部修改函数的命名返回值。多个 defer 语句按 LIFO 顺序执行。
defer 最常用是保证一个文件使用完以后关闭defer file.Close()
panic 和 revover,前文已经阐述过 Go 语言将错误和异常区分对待,错误(可预期的)常通过函数的返回值形式实现,而对于“不可能发生”的情况(异常)我们使用内置的panic()函数。
当内置的panic()函数被调用时,外围函数或者方法的执行会立即中止。然后,任何延迟执行的函数或者方法都会被调用,就像返回一样。最后,调用返回到该外围函数的调用者,就像该外围调用函数或者方法调用了panic()一样,该过程在调用栈中重复发生:函数停止执行,调用延迟执行函数等。当到达main()函数时不再有可以返回的调用者,因此这时程序会中止,并将包含传入原始panic()函数中的值的调用栈信息输出到os.Stderr。
上面所描述的只是一个异常发生时正常情况下所展开的。然而,如果其中有个延迟执行的函数或者方法包含一个对内值的recover()函数(可能值在一个延迟执行的函数或者方法中调用),该异常展开就会中止(被捕获)。这种情况下,我们就能够以任何我们想要的方式相应该异常(忽略,转错误等)。
异常和错误的使用规范
绝大多数情况下,Go 语言标准库实验嗯 error 值而非异常。(标准库的规范),对于我们手写的自定义的包,尽量不要使用panic(),如果要使用,也要避免异常离开这个自定义包的边界,可以用recover()捕获异常并返回一个相应的错误值,就像标准库中所作的那样。
作为一个程序员,如果程序中有逻辑错误,我们希望程序能够立马崩溃,以便我们可以发现并修改该问题。但一旦程序部署好了,我们就不想让我们的程序崩溃。
对于任何特殊情况下可能运行也G可能不运行的函数或者方法,如果调用了panic()函数或者调用了发生异常的函数或者方法,我们应该使用recover()以保证将异常转换成错误。理想情况下,recover()函数应该在尽可能接近于panic()的地方背调用,并在设置其外围函数 error 返回值之前尽可能合理的将程序恢复到健康状态。对于 main 包的main()函数,我们可以放入一个“捕获一切”的recover函数,用于记录任何捕获的异常。
自定义函数
这里内容有点繁杂,需要自己多动手实践体会
关于返回值:如果函数有返回值,则函数必须至少有一个 return 语句或者panic()调用,如果返回值不是命名的,则 return 语句必须指定和返回值列表一样多的值。如果有命名,也尽量写全 return(空 return 语句虽然合法,但是被认为是一种拙劣的写法。)
函数参数
函数调用可以作为函数参数
需要类型和数量匹配,如
Heron(a,b,c)与Heron(PythagoreanTriple(i,i+1)),其中PythagoreanTriple(i,i+1)返回三个整数值。可变函数参数
最后一个类型前面加一个省略号,在函数里面这个参数实际上变成了一个对应参数类型的切片。如我们有一个签名是
Join(first string, xs ...String)的函数,xs类型实际上是[]string常见的可变参数设置是:完全任意(可空参),至少一参,至少两参(前面单独列出即可)。
可选参数
Go 没有直接支持可选参数,要实现也不难,只需增加一个额外的结构体即可,而且 Go 语言能保证所有值都会被初始化为零值。
一个比较优雅的做法是这样定义函数 ProcessItems(items Items, options Options),其中 Options 结构体保存了所有其他参数的值,其结构为:
1 | |
Go 保证结构体传入初始化为零值,大部分需要默认场合(全零值的情况),调用很简单,如果需要制定一个或者多个,则填入对应的字段名即可,如下:
1 | |
init()函数和 main()函数
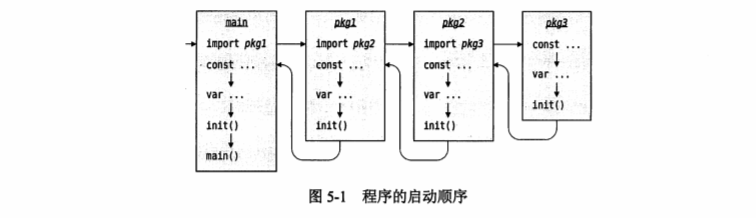
Go 语言保留两个函数名:init()函数用来导入包后执行,全main()函数,作为入口,这两个函数不显示调用,也不可接受任何参数,不返回任何结果。建议一个包最多只用一个init()函数。
程序启动顺序如下:
闭包
这是个重要的概念,所谓闭包就是一个函数“捕获”了和它在同意作用域地其他常量和变量(或许可以理解成声明时就调用了在这个作用域地其他常量和变量),闭包使用这些捕获的量且不关心它们是否已经超出作用域,所以只要闭包还在使用它,这些变量就还会存在。在 Go 语言里,所有的匿名函数(Go 语言规范中称之为函数字面量)都是闭包。
闭包没有名字,通常使用方法时赋值给一个变量或者将它放在一个数据结构里(如映射/切片)。
另外,工厂函数(装饰函数)返回的也常为一个函数闭包,函数闭包也常出现在一些函数参数中
运行时选择函数
在 Go 语言里,函数属于第一类值(first-class value),也就是说,你可以将它保存到一个变量(实际上是一个引用)里,这样我们就可以在运行时决定要执行哪一个函数(比 if-else 运行时选择来的快)。
根据书上写的实验
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!